I did a previous blog providing a side-by-side comparisons of R’s {tidyverse} to Python for various data manipulation techniques. I’ve also talked extensively about using {tidymodels} for model fitting (see HERE and HERE). Today, we will work through a tutorial on how to fit the same random forest model in {tidyverse} and Scikit Learn.
This will be a side-by-side view of both coding languages.The tutorial will cover:
- Loading the data
- Basic exploratory data analysis
- Creating a train/test split
- Hyperparameter tuning by creating cross-validated folds on the training data
- Identifying the optimal hyperparameters and fitting the final model
- Applying the final model to the test data and evaluating model performance
- Saving the model for downstream use
- Loading the saved model and applying it to new data
To get the full code for each language and follow along with the tutorial visit my GITHUB page.
The Data
The data comes the tidytuesday project from 4/4/2023. The data set is Premier League match data (2021 – 2022) that provides a series of features with the goal of predicting the final result (Full Time Result, FTR) as to whether the home team won, the away team won, or the match resulted in a draw.
Load Data & Packages
First, we load the data directly from the tidytuesday website in both languages.

Exploratory Data Analysis
Next, we perform some exploratory data analysis to understand the potential features for our model.
- Check each column for NAs
- Plot a count of the outcome variable across the three levels (H = home team wins, A = away team wins, D = draw)
- Select a few features for our model and then create box plots for each feature relative to the 3 levels of our outcome variable



Train/Test Split
We being the model building process by creating a train/test split of the data.

Create a Random Forest Classifier Instance
This is basically telling R and python that we want to build a random forest classifier. In {tidymodels} this is referred to as “specifying the model engine”.
Hyperparameter Tuning on Cross Validated Folds
The two random forest hyperparameters we will tune are:
- The number of variables randomly selected for candidate model at each split (R calls this mtry while Python calls it max_features)
- The number of trees to grow (R calls this trees and Python calls it n_estimators)
In {tidymodels} we will specify 5 cross validated folds on the training set, set up a recipe, which explains the model we want (predicting FTR from all of the other variables in the data), put all of this into a single workflow and then set up our tuning parameter grid.
In Scikit Learn, we set up a dictionary of parameters (NOTE: they must be stored in list format) and we will pass them into a cross validation structure that performs 5-fold cross-validation in parallel (to speed up the process). We then pass this into the GridSearchCV() function where we specify the model we are fitting (random forest), the parameter grid that we’ve specified, and how we want to compare the random forest models (scoring). Additionally, we’ll set n_jobs = -1 to allow Python to use all of the cores on our machine.
While the code looks different, we’ve essentially set up the same process in both languages.

Tune the model on the training data
We can now tune the hyperparameters by applying the cross-validated folds procedure to the training data.
Above, we indicated to Python that we wanted some parallel processing, to speed up the process. In {tidyverse} we specify parallel processing by setting up the number of cores we’d like to use on our machine. Additionally, we will want to save the results of each cross-validated iteration, so we use the control_sample() function to do this. All of these steps were specified in Python, above, so we are ready to now apply cross-validation to our training dataset and tune the hyperparameters.

Get the best parameters
Both R and Python provide numerous objects to explore the output for each of the cross-validated folds. I’ve placed some examples in the respective codes in the GITHUB page. For our purposes, we are most interested in the optimal number of variables and trees. Both coding languages found 4 and 400 to be the optimal number of variables and trees, respectively.

Fitting the Final Model
Now that we have the optimal hyperparameter values, we can refit the model. In both {tidymodels} and Scikit learn, we’ll just refit a random forest with those optimal values specified.

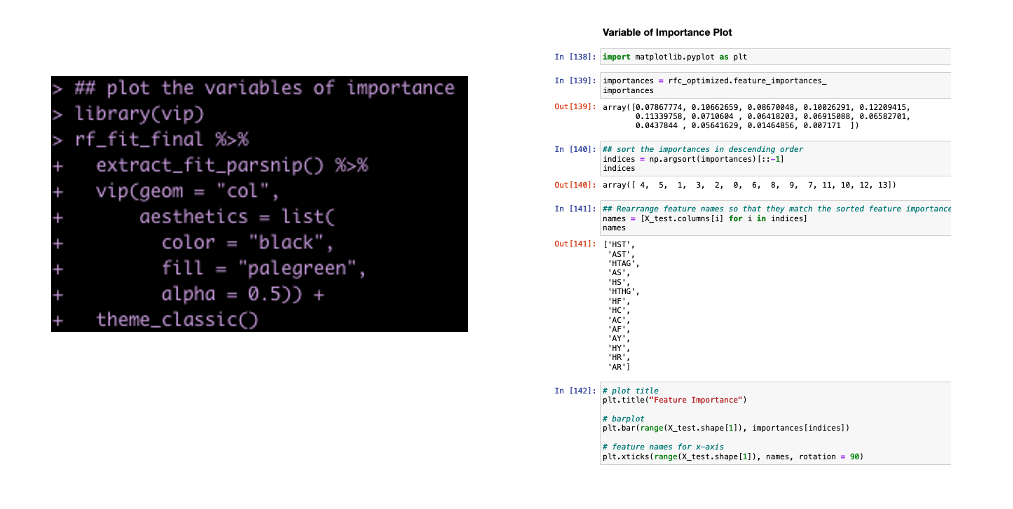
Variable Importance Plot
It’s helpful to see which variables were the most important contributors to the model’s predictions.
Side Note: This takes more code in python than in R. This is one of the drawbacks I’ve found with python compared to R. I can do things more efficiently and with less code in R than in python. I often find I have to work a lot harder in Scikit Learn to get model outputs and information about the model fit. It’s all in there but it is not clearly accessible (to me at least) and plotting in matplotlib is not as clean as plotting in ggplot2.

Get Model Predictions on the Test Set
Both languages offer some out of the box options for describing the model fit info. If you want more than this (which you should, because this isn’t much to go off of), then you’ll have to extract the predicted probabilities and the actual outcomes and code some additional analysis (potentially a future blog article).

Save The Model
If we want to use this model for any downstream analysis we will need to save it.

Load the Model and Make Predictions
Once we have the model saved we can load it and apply it to any new data that comes in. Here, our new data will just be a selection of rows from the original data set (we will pretend it is new).
NOTE: Python is 0 indexed while R is indexed starting at 1. So keep that in mind if selecting rows from the original data to make the same comparison in both languages.

Wrapping Up
Both {tidymodels} and Scikit Learn provide users with powerful machine learning frameworks for conducting analysis. While the code syntax differs, the general concepts are the same, so bouncing between the two languages shouldn’t be to cumbersome. Hopefully this tutorial provided a nice overview of how to conduct the same analysis in both languages, offering a bridge for those trying to learn Python from R and vice versa.
All code is available on my GITHUB page.