Julia Silge recently posted a new #tidytuesday blog article using the {tidymodels} package to build bootstrapped samples of a data set and then fit a linear to those bootstrapped samples as a means of exploring the uncertainty around the model coefficients.
I’ve written a few pieces on resampling methods here (See TidyX Episode 98 and THIS article I wrote about how to approximate a Bayesian Posterior Prediction). I enjoyed Julia’s article (and corresponding screen cast) so I decided to expand on what she shared, this time using Baseball data, and show additional ways of evaluating the uncertainty in model coefficients as well as extending out the approach to using the bootstrapped models for prediction uncertainty.
Side Note: We interviewed Julia on TidyX Episode 86.
Load Packages & Data
We will be using the {Lahman} package in R to obtain hitting statistics of all players with a minimum of 200 at bats, from the 2010 season or greater.
Our goal here is to work with a simple linear model that regresses the dependent variable, Runs, on the independent variable, Hits. (Note: Runs is really a count variable, so we could have modeled this differently, but we will stick with a simple linear model for purposes of simplicity and to show how bootstrapping can be used to understand uncertainty.)
## packages
library(tidyverse)
library(Lahman)
library(tidymodels)
library(broom)
theme_set(theme_light())
## data
d <- Batting %>%
filter(yearID >= 2010) %>%
select(playerID, yearID, AB, R, H) %>%
group_by(playerID, yearID) %>%
summarize(across(.cols = everything(),
~sum(.x)),
.groups = "drop") %>%
filter(AB >= 200)
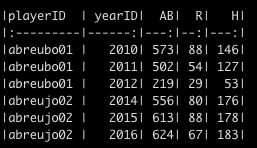
d %>%
head() %>%
knitr::kable()
Exploratory Data Analysis
Before we get into the model, we will just make a simple plot of the data and produce some basic summary statistics (all of the code for this will is available on my GITHUB page).


Linear Regression
First, we produce a simple linear regression using all the data to see what the coefficients look like. I’m doing this to have something to compare the bootstrapped regression coefficients to.
## Model
fit_lm <- lm(R ~ H, data = d)
tidy(fit_lm)
 It looks like, for every 1 extra hit that a player gets it increases their Run total, on average, by approximately 0.518 runs. The intercept here is not interpretable since 0 hits wouldn’t lead to negative runs. We could mean scale the Hits variable to fix this problem but we will leave it as is for the this example since it isn’t the primary focus. For now, we can think of the intercept as a value that it just helping calibrate our Runs data to a fixed value on the y-axis.
It looks like, for every 1 extra hit that a player gets it increases their Run total, on average, by approximately 0.518 runs. The intercept here is not interpretable since 0 hits wouldn’t lead to negative runs. We could mean scale the Hits variable to fix this problem but we will leave it as is for the this example since it isn’t the primary focus. For now, we can think of the intercept as a value that it just helping calibrate our Runs data to a fixed value on the y-axis.
{tidymodels} regression with bootstrapping
First, we create 1000 bootstrap resamples of the data.
### 1000 Bootstrap folds
set.seed(9183)
boot_samples <- bootstraps(d, times = 1000)
boot_samples

Next, we fit our linear model to each of the 1000 bootstrapped samples. We do this with the map() function, as we loop over each of the splits.
fit_boot <- boot_samples %>%
mutate(
model = map(
splits,
~ lm(R ~ H,
data = .x)
))
fit_boot
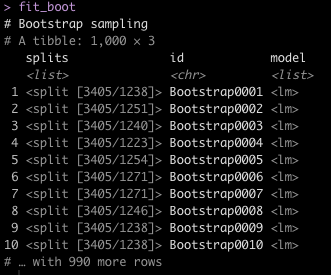
Notice that we have each of our bootstrap samples stored in a list (splits) with a corresponding bootstrap id. We’ve added a new column, which stores a list for each bootstrap id representing the linear model information for that bootstrap sample.
Again, with the power of the map() function, we will loop over the model lists and extract the model coefficients, their standard errors, t-statistics, and p-values for each of the bootstrapped samples. We do this using the tidy() function from the {broom} package.
boot_coefs <- fit_boot %>%
mutate(coefs = map(model, tidy))
boot_coefs %>%
unnest(coefs)
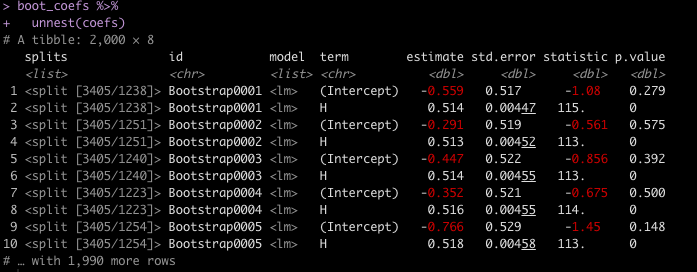
The estimate column is the coefficient value for each of the model terms (Intercept and H). Notice that the values bounce around a bit. This is because the bootstrapped resamples are each slightly different as we resample the data, with replacement. Thus, slightly different models are fit to each of those samples.
Uncertainty in the Coefficients
Now that we have all of 1000 different model coefficients, for each of the resampled data sets, we can begin to explore their uncertainty.
We start with a histogram of the 1000 model coefficients to show how large the uncertainty is around the slope and intercept.
boot_coefs %>%
unnest(coefs) %>%
select(term, estimate) %>%
ggplot(aes(x = estimate)) +
geom_histogram(color = "black",
fill = "grey") +
facet_wrap(~term, scales = "free_x") +
theme(strip.background = element_rect(fill = "black"),
strip.text = element_text(color = "white", face = "bold"))
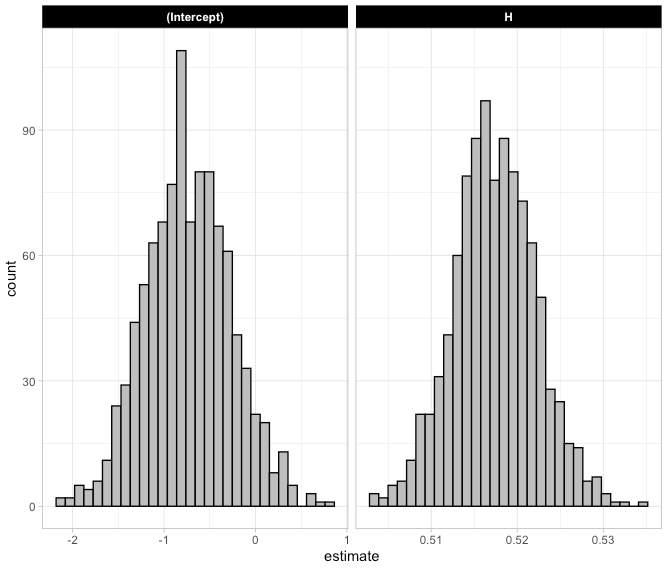
We can also calculate the mean and standard deviation of the 1000 model coefficients and compare them to what we obtained with the original linear model fit to all the data.
## bootstrapped coefficient's mean and SD
boot_coefs %>%
unnest(coefs) %>%
select(term, estimate) %>%
group_by(term) %>%
summarize(across(.cols = estimate,
list(mean = mean, sd = sd)))
# check results against linear model
tidy(fit_lm)

Notice that the values obtained by taking the mean and standard deviation of the 1000 bootstrap samples is very close the model coefficients from the linear model. They aren’t exact because the bootstraps are unique resamples. If you were to change the seed or not set the seed when producing bootstrap samples you would get different coefficients yet again. However, the bootstrap coefficients will always be relatively close approximations of the linear model regression coefficients within some margin of error.
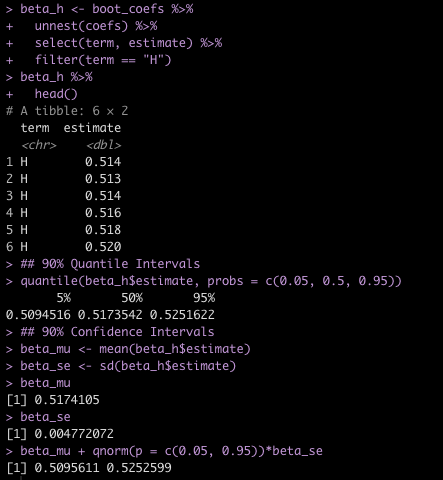
We can explore the coefficient for Hits, which was our independent variable of interest, by extracting its coefficients and calculating things like 90% Quantile Intervals and 90% Confidence Intervals.
beta_h <- boot_coefs %>%
unnest(coefs) %>%
select(term, estimate) %>%
filter(term == "H")
beta_h %>%
head()
## 90% Quantile Intervals
quantile(beta_h$estimate, probs = c(0.05, 0.5, 0.95))
## 90% Confidence Intervals
beta_mu <- mean(beta_h$estimate)
beta_se <- sd(beta_h$estimate)
beta_mu
beta_se
beta_mu + qnorm(p = c(0.05, 0.95))*beta_se
Of course, if we didn’t want to go through the trouble of coding all that, {tidymodels} provides us with a helper function called int_pctl() which will produce 95% Confidence Intervals by default and we can set the alpha argument to 0.1 to obtain 90% confidence intervals.
## can use the built in function from {tidymodels}
# defaults to a 95% Confidence Interval
int_pctl(boot_coefs, coefs)
# get 90% Confidence Interval
int_pctl(boot_coefs, coefs, alpha = 0.1)
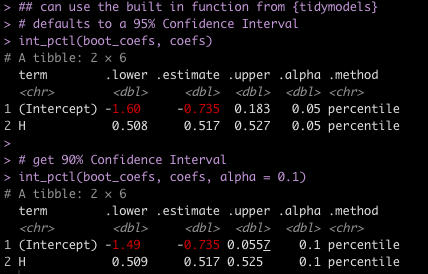
Notice that the 90% Confidence Interval for the Hits coefficient is the same as I calculated above.
Using the Bootstrapped Samples for Prediction
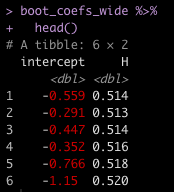
To use these bootstrapped samples for prediction I will first extract the model coefficients and then structure them in a wide data frame.
boot_coefs_wide <- boot_coefs %>%
unnest(coefs) %>%
select(term, estimate) %>%
mutate(term = case_when(term == "(Intercept)" ~ "intercept",
TRUE ~ term)) %>%
pivot_wider(names_from = term,
values_from = estimate,
values_fn = 'list') %>%
unnest(cols = everything())
boot_coefs_wide %>%
head()
In a previous blog I talked about three types of predictions (as indicated in Gelman & Hill’s Regression and Other Stories) we might choose to make from our models:
- Point prediction
- Point prediction with uncertainty
- A predictive distribution for a new observation in the population
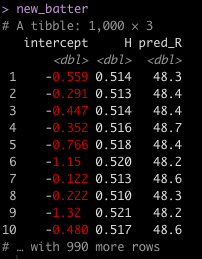
Let’s say we observe a new batter with 95 Hits on the season. How many Runs would we expect this batter to have?
To do this, I will apply the new batters 95 hits to the coefficients for each of the bootstrapped regression models, producing 1000 estimates of Runs for this hitter.
new_H <- 95
new_batter <- boot_coefs_wide %>%
mutate(pred_R = intercept + H * new_H)
new_batter
We can plot the distribution of these estimates.
## plot the distribution of predictions
new_batter %>%
ggplot(aes(x = pred_R)) +
geom_histogram(color = "black",
fill = "light grey") +
geom_vline(aes(xintercept = mean(pred_R)),
color = "red",
linetype = "dashed",
size = 1.4)
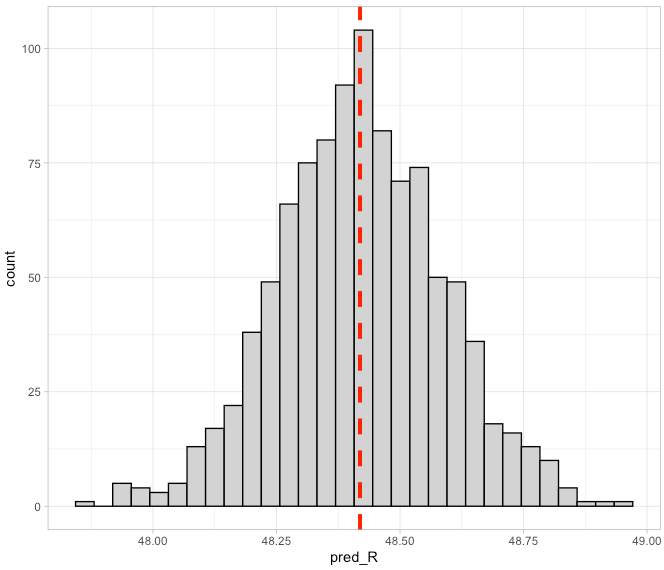
Next, we can get our point prediction by taking the average and standard deviation over the 1000 estimates.
## mean and standard deviation of bootstrap predictions
new_batter %>%
summarize(avg = mean(pred_R),
SD = sd(pred_R))
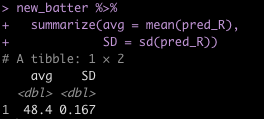
We can compare this to the predicted value and standard error from the original linear model.
## compare to linear model
predict(fit_lm, newdata = data.frame(H = new_H), se = TRUE)

Pretty similar!
For making predictions about uncertainty we can make predictions either at the population level, saying something about the average person in the population (point 2 above) or at the individual level (point 3 above). The former would require us to calculate the Confidence Interval while the latter would require the Prediction Interval.
(NOTE: If you’d like to read more about the different between Confidence and Prediction Intervals, check out THIS BLOG I did, discussing both from a Frequentist and Bayesian perspective).
We’ll start by extracting the vector of estimated runs and then calculating 90% Quantile Intervals and 90% Confidence Intervals.
## get a vector of the predicted runs
pred_runs <- new_batter %>%
pull(pred_R)
## 90% Quantile Intervals
quantile(pred_runs, probs = c(0.05, 0.5, 0.95))
## 90% Confidence Interval
mean(pred_runs) + qnorm(p = c(0.025, 0.975)) * sd(pred_runs)
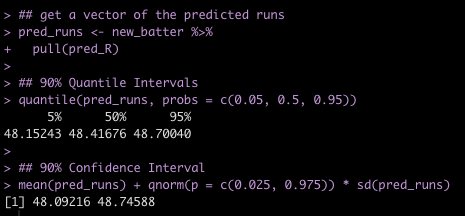
We can compare the 90% Confidence Interval of our bootstrapped samples to that of the linear model.
## Compare to 90% confidence intervals from linear model
predict(fit_lm, newdata = data.frame(H = new_H), interval = "confidence", level = 0.90)

Again, pretty close!
Now we are ready to create prediction intervals. This is a little tricky because we need the model sigma from each of the bootstrapped models. The model sigma is represented as the Residual Standard Error in the original linear model output. Basically, this informs us about how much error there is in our model, indicating how far off our predictions might be. In this case, our predictions are, on average, off by about 10.87 Runs.

To extract this residual standard error value for each of the bootstrapped resamples, we will use the glance() function from the {broom} package, which produces model fit variables. Again, we use the map() function to loop over each of the bootstrapped models, extracting sigma.
boot_sigma <- fit_boot %>%
mutate(coefs = map(model, glance)) %>%
unnest(coefs) %>%
select(id, sigma)
Next, we’ll recreate the previous wide data frame of the model coefficients but this time we retain the bootstrap id column so that we can join the sigma value of each of those models to it.
## Get the bootstrap coefficients and the bootstrap id to join the sigma with it
boot_coefs_sigma <- boot_coefs %>%
unnest(coefs) %>%
select(id, term, estimate) %>%
mutate(term = case_when(term == "(Intercept)" ~ "intercept",
TRUE ~ term)) %>%
pivot_wider(names_from = term,
values_from = estimate,
values_fn = 'list') %>%
unnest(everything()) %>%
left_join(boot_sigma)
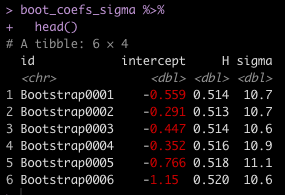
Now we have 4 columns for each of the 1000 bootstrapped samples: An Id, an intercept, a coefficient for Hits, and a residual standard error (sigma).
We make a prediction for Runs the new batter with 95 Hits. This time, we add in some model error by drawing a random number with a mean of 0 and standard deviation equal to the model’s sigma value.
## Now make prediction using a random draw with mean = 0 and sd = sigma for model uncertainty
new_H <- 95
# set seed so that the random draw for model error is replicable
set.seed(476)
new_batter2 <- boot_coefs_sigma %>%
mutate(pred_R = intercept + H * new_H + rnorm(n = nrow(.), mean = 0, sd = sigma))
new_batter2 %>%
head()
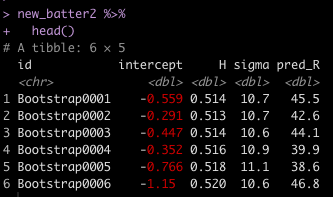
Again, we can see that we have some predicted estimates for the number of runs we might expect for this new hitter. We can take those values and produce a histogram as well as extract the mean, standard deviation, and 90% Prediction Intervals.
## plot the distribution of predictions
new_batter2 %>%
ggplot(aes(x = pred_R)) +
geom_histogram(color = "black",
fill = "light grey") +
geom_vline(aes(xintercept = mean(pred_R)),
color = "red",
linetype = "dashed",
size = 1.4)
## mean and standard deviation of bootstrap predictions
new_batter2 %>%
summarize(avg = mean(pred_R),
SD = sd(pred_R),
Low_CL90 = avg - 1.68 * SD,
High_CL90 = avg + 1.68 * SD)
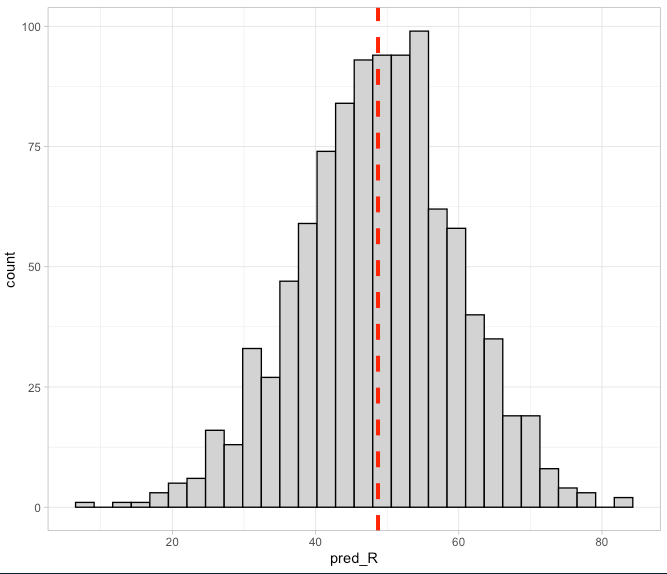
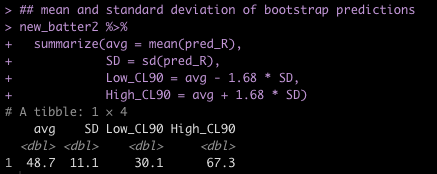
Notice that while the average number of Runs is relatively unchanged, the Prediction Intervals are much larger! That’s because we are incorporating more uncertainty into our Prediction Interval to try and say something about someone specific in the population versus just trying to make a statement about the population on average (again, check out THIS BLOG for more details).
Finally, we can compare the results from the bootstrapped models to the prediction intervals from our original linear model.
## compare to linear model
predict(fit_lm, newdata = data.frame(H = new_H), interval = "predic", level = 0.9)

Again, pretty close to the same results!
Wrapping Up
Using things like bootstrap resampling and simulation (NOTE: They are different!) is a great way to explore uncertainty in your data and in your models. Additionally, such techniques become incredibly useful when making predictions because every prediction about the future is riddled with uncertainty and point estimates rarely ever do us any good by themselves. Finally, {tidymodels} offers a nice framework for building models and provides a number of helper functions that take a lot of the heavy lifting and coding out of your hands, allowing you to think harder about the models you are creating and less about writing for() loops and vectors.
(THIS BLOG contains my simple {tidymodels} template if you are looking to get started using the package).
If you notice any errors, please let me know!
To access the entire code for this article, please see my GITHUB page.


