
A colleague contacted me last week asking about how they could fill in missing values in their data frame with 0’s. Let’s face it, missing values are an unfortunate reality when working with data and they can be a real pain in the butt. There have been a number of papers that discuss ways of handing missing values (e.g., various imputation approaches) and it is not my intention to address those here as the approach you choose to use would depend on the data and what you are trying to do.
My goal with this installment of R Tips & Tricks is to provide you with a way to remove NA’s, NaN’s, and Inf’s from your data set or to replace them in with some specified value (e.g., the column median or 0). The latter approach can also be used if you wanted to impute values, as suggested above (e.g, use a regression equation to forecast what the value would be given other data, used as independent variables in the model, in your data set).
Create Some Data
First we need to load the tidyverse package and create some data.
## Load tidyverse library(tidyverse) ## Create fake data df <- tibble( var1 = c(4, 2, Inf, 3, NA, 6, NA, NaN, 44, 23, 78), var2 = c(7.8, NaN, 70, 1, 8, -Inf, NA, 99, 12, 3, 2.2))
As we can see, our data has a bunch of NA, NaN, Inf, and -Inf characters in it. Creating the data as a tibble allows us to quickly identify these characters as they are colored in red:

How many missing values and Inf’s are we dealing with?
Before removing rows with NA’s and Inf’s or trying to impute values it is best to see how many of these characters are in each columns. Below is some code to quickly evaluate this but if you have a larger data set and want to get other summary measures for each column you may want to check out one of my older posts on how to build a data dictionary.
## Get a count of the number of NA, NaN, and Inf in each column
data.frame(NA_cols = sapply(df, function(x) sum(length(which(is.na(x))))),
NaN_cols = sapply(df, function(x) sum(length(which(is.nan(x))))),
Inf_cols = sapply(df, function(x) sum(length(which(is.infinite(x)))))) %>%
t()
The above code produces a table of counts of NA, NaN, and Inf’s in both of our columns (var1, var2).
Removing the rows with NA, NaN, and Inf
Sometimes, you might just want to remove the rows with missing values or Inf.
NOTE: If you are going to do this it is critical that you have a good reason to do so and you know exactly why you are doing it and how it might change any outcomes generated from your analysis!
There are two easy ways to do this in tidyverse. One way is to simply remove these characters one-by-one. In this way, you can simply indicate which column you want and which rows you’d like to remove.
# One row at a time
df %>%
filter(!is.na(var1),
!is.na(var2),
!is.infinite(var1),
!is.infinite(var2))
The other option (useful if you have a data set with a large number of columns) is to pass the above functions to any columns that are integers.
# All numeric rows at once df %>% filter_if(is.numeric, all_vars(!is.na(.))) %>% filter_if(is.numeric, all_vars(!is.infinite(.)))
Both approaches produce the same result:

Replace NA, NaN, and Inf with a specific value
Finally, we can replace the NA, NaN, or Inf with a specific value. In the below code, I replace Na and NaN with the median value of the respective column and I replace Inf and -Inf with a 0. If you had an equation for imputing values, this would also be a way that you could do it.
## Use tidyverse to convert NA and NaN to the median of column 1 and Inf to 0 in both columns
df <- df %>% mutate(var1_new = ifelse(is.na(var1), median(var1, na.rm = T), ifelse(
is.infinite(var1), 0, var1)),
var2_new = ifelse(is.na(var2), median(var2, na.rm = T), ifelse(
is.infinite(var2), 0, var2)))
After running that code we can see in the two new columns where the characters were replaced with the specified values.
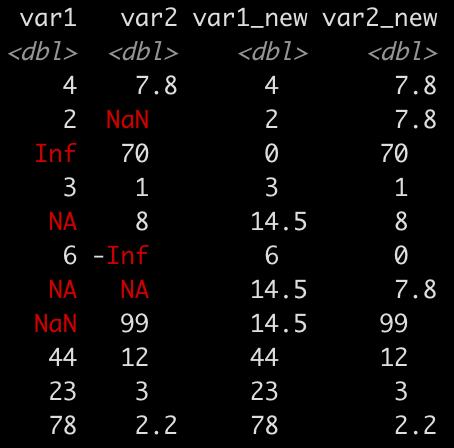
Missing values can bring all sorts of issues in data clean up and analysis. Think hard before you decide to remove them or what approach you might take to impute values. In this case, we used median imputation for NA and NaN but there are a number of other approaches that are more rigorous and will offer more reliable results.
The code for this blog is available on my GITHUB Page.