
In my previous post, I did a bit of impromptu analysis on some Powerlifting data provided from the TidyTusday project.
When sitting down to work with a new data set it is important to familiarize yourself with the variables in each column, get a grasp for what sort of values you may be dealing with, and quickly identify any potential issues with the data that may require your attention.
For looking at the type of variables you are dealing with the functions str() in base R or glimpse() in tidyverse can be useful. If it’s summary statistics you’re after, the psych package’s describe() function will do the trick. The summary() function in base R can also be useful for getting min, max, mean, median, IQR, and the number of missing values (NA) in each column.
The issue with this is that you have to go through a few steps to get the info you want — variable types, number of missing values, and summary statistics. Thus, I decided to create my own data dictionary function. After passing your data frame to the function, you will get the name of each variable, the variable type, the number of missing values for each variable, the total amount of data (rows) for each value, and a host of summary statistics such as mean, standard deviation, median, standard error, min, max, and range. While the function defaults to printing the results in your R console you can choose to set the argument print_table = “Yes” and the results will be returned in a nice table that you can use for reports or presentations to colleagues.
Let’s take a look at function in action.
First, we will create some fake data:
Names <- c("Sal", "John", "Jeff", "Karl", "Ben")
HomeTown <- c("CLE", "NYC", "CHI", "DEN", "SEA")
var1 <- rnorm(n = length(Names), mean = 10, sd = 2)
var2 <- rnorm(n = length(Names), mean = 300, sd = 150)
var3 <- rnorm(n = length(Names), mean = 1000, sd = 350)
var4 <- c(6, 7, NA, 3, NA)
df <- data.frame(Names, HomeTown, var1, var2, var3, var4)
df
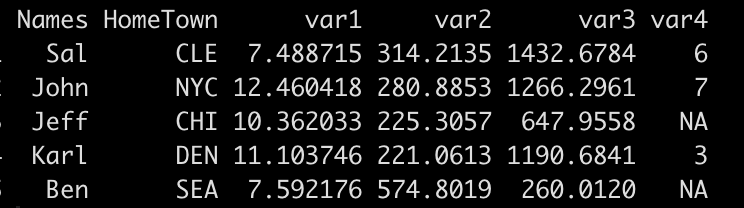
We can see from the output that the code includes a few NA values in the var4 column. Additionally, the first two columns are not numeric values. We can run the data_dict() function I’ve created to get a read out of the data we are looking at.
First, let’s look at the output in the R console:
# without table data_dict(df, print_table = "No")

We are immediately returned an output that consolidates some key information for helping us quickly evaluate our data set.
By setting the argument print_table = “Yes” we will get our result in a nice table format.
# with table data_dict(df, print_table = "Yes")

Let’s look at the results in table format for a much larger data set — the Lahman Baseball Batting data set.
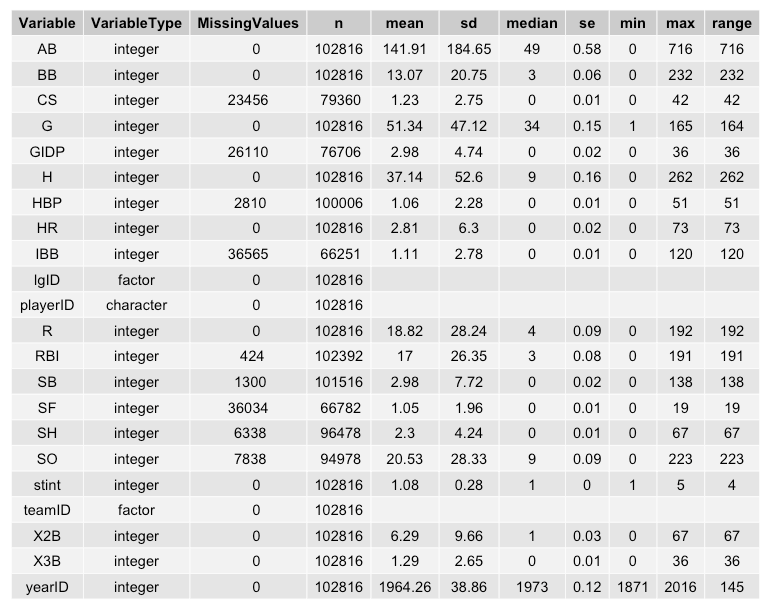
As you can see, it is a pretty handy function. Very quickly we can identify:
1) The types of variables in our data
2) The amount of data in each column
3) The number of missing values in each column
4) A variety of summary statistics
If you’re interested in using the function, you can obtain it on my GitHub page.