
We often construct models for the purpose of estimating some future value or outcome. While point estimates for a forecasting future outcomes are interesting it is important to remember that the future contains a lot of uncertainty. As such, a reflection of this uncertainty is often conveyed using confidence intervals (which make a statement about the uncertainty of a population mean) or prediction intervals (which make a statement about a new/future observation for an individual within the population).
This tutorial will walk through how to calculate confidence intervals and prediction intervals by hand and then show the corresponding R functions for obtaining these values. We will finish by building the same model using a Bayesian framework and calculate the highest posterior density intervals and prediction intervals.
All of code is accessible through my GITHUB page.
Loading Packages & Data
We will use the Lahman baseball data set. For the purposes of this example, we will constrain our data to all MLB seasons after 2009 and players who had at least 250 At Bats in those seasons.
library(tidyverse)
library(broom)
library(Lahman)
theme_set(theme_minimal())
data(Batting)
df <- Batting %>%
filter(yearID >= 2010,
AB >= 250)
EDA
Let’s explore the relationship between Hits (H) and Runs Batted In (RBI) in our data set.
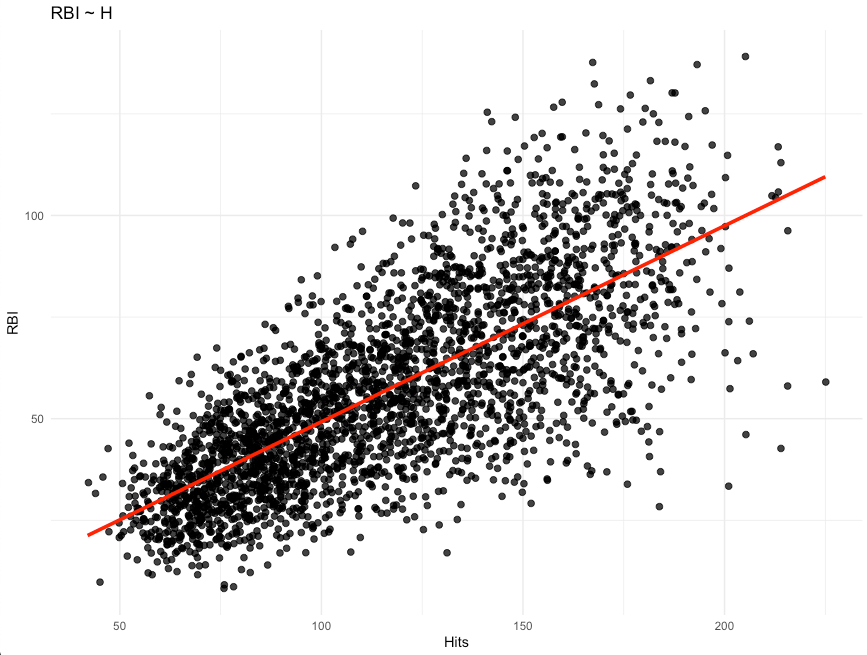
cor.test(df$H, df$RBI)
We see a very positive correlation suggesting that as a player gets more hits they tend to also have more RBI’s.
A Simple Regression Model
We will build a simple model that regresses RBI’s on Hits.
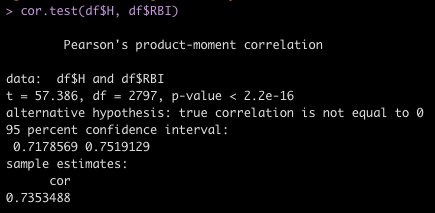
rbi_fit <- df %>% lm(RBI ~ H, data = .) tidy(rbi_fit) confint(rbi_fit)
- Using tidy() from the broom package, we see that for every additional Hit we estimate a player to increase their RBI, on average, by 0.482.
- We use the confint() function to produce the confidence intervals around the model coefficients.
Estimating Uncertainty
We can use the above model to forecast the expected number of RBI’s for a player given a number of hits.
For example, a player that has 100 hits would be estimated to produce approximately 49 RBI’s.
hits <- 100 pred_rbi <- round(rbi_fit$coef[1] + rbi_fit$coef[2]*hits, 1) pred_rbi

49 RBI’s is rather precise. There is always going to be some uncertainty around a number like this. For example, a player could be a good hitter but play on a team with poor hitters who don’t get on base thus limiting the possibility for all the hits he is getting to lead to RBI’s.
There are two types of questions we may choose to answer around our prediction:
- Predict the average RBI’s for players who get 100 hits.
- Predict the average RBI’s for a single player who gets 100 hits.
The point estimate, which we calculated above, will be the same for these two questions. Where they will differ is in the uncertainty we have around that estimate. Question 1 is a statement about the population (the average RBIs for all players who had 100 hits) while question 2 is a statement about an individual (the average RBI’s for a single player). Consequently, the confidence interval that we calculate to estimate our uncertainty for question 1 will be smaller than the prediction interval that we calculate to estimate our uncertainty for question 2.
Necessary Information for Computing Confidence Intervals & Prediction Intervals
In order to calculate the confidence interval and prediction interval by hand we need the following pieces of data:
- The model degrees of freedom.
- A t-critical value corresponding to the level of uncertainty we are interested in (here we will use 95%).
- The average number of hits (our independent variable) observed in our data.
- The standard deviation of hits observed in our data.
- The residual standard error of our model.
- The total number of observations in our data set.
## Model degrees of freedom model_df <- rbi_fit$df.residual ## t-critical value for a 95% level of certainty level_of_certainty <- 0.95 alpha <- 1 - (1 - level_of_certainty) / 2 t_crit <- qt(p = alpha, df = model_df) t_crit ## Average & Standard Deviation of Hits avg_h <- mean(df$H) sd_h <- sd(df$H) ## Residual Standard Error of the model and Total Number of Observations rse <- sqrt(sum(rbi_fit$residuals^2) / model_df) N <- nrow(df)
Calculating the Confidence Interval
We can calculate the 95% confidence level by hand using the following equation:
CL95 = t.crit * rse * sqrt(1/N + ((hits – avg.h)^2) / ((N – 1) * sd.h^2))
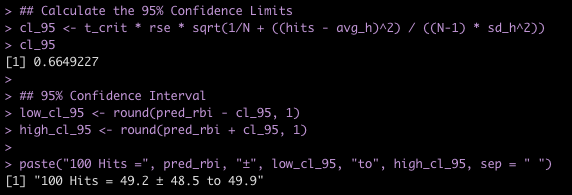
## Calculate the 95% Confidence Limits
cl_95 <- t_crit * rse * sqrt(1/N + ((hits - avg_h)^2) / ((N-1) * sd_h^2))
cl_95
## 95% Confidence Interval
low_cl_95 <- round(pred_rbi - cl_95, 1)
high_cl_95 <- round(pred_rbi + cl_95, 1)
paste("100 Hits =", pred_rbi, "±", low_cl_95, "to", high_cl_95, sep = " ")
If we don’t want to calculate the Confidence Interval by hand we can simply use the predict() function in R. We obtain the same result.
round(predict(rbi_fit, newdata = data.frame(H = hits), interval = "confidence", level = 0.95), 1)

Calculating the Prediction Interval
Notice below that the prediction interval uses the same equation as the confidence interval with the exception of adding 1 before 1/N. As such, the prediction interval will be wider as there is more uncertainty when attempting to make a prediction for a single individual within the population.
PI95 = t.crit * rse * sqrt(1 + 1/N + ((hits – avg.h)^2) / ((N – 1) * sd.h^2))
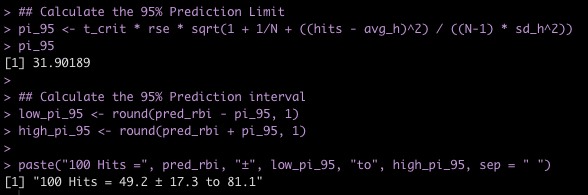
## Calculate the 95% Prediction Limit
pi_95 <- t_crit * rse * sqrt(1 + 1/N + ((hits - avg_h)^2) / ((N-1) * sd_h^2))
pi_95
## Calculate the 95% Prediction interval
low_pi_95 <- round(pred_rbi - pi_95, 1)
high_pi_95 <- round(pred_rbi + pi_95, 1)
paste("100 Hits =", pred_rbi, "±", low_pi_95, "to", high_pi_95, sep = " ")
Again, if we don’t want to do the math by hand, we can simply use the the predict() function and change the interval argument from confidence to prediction.
round(predict(rbi_fit, newdata = data.frame(H = hits), interval = "prediction", level = 0.95), 1)

Visualizing the 95% Confidence Interval and Prediction Interval
Instead of deriving the point estimate, confidence interval, and prediction interval for a single observation of hits, let’s derive them a variety of number of hits and then plot the intervals over our data to see what they look like.
We could simply use ggplot2 to draw a regression line with 95% confidence intervals over top of our data.
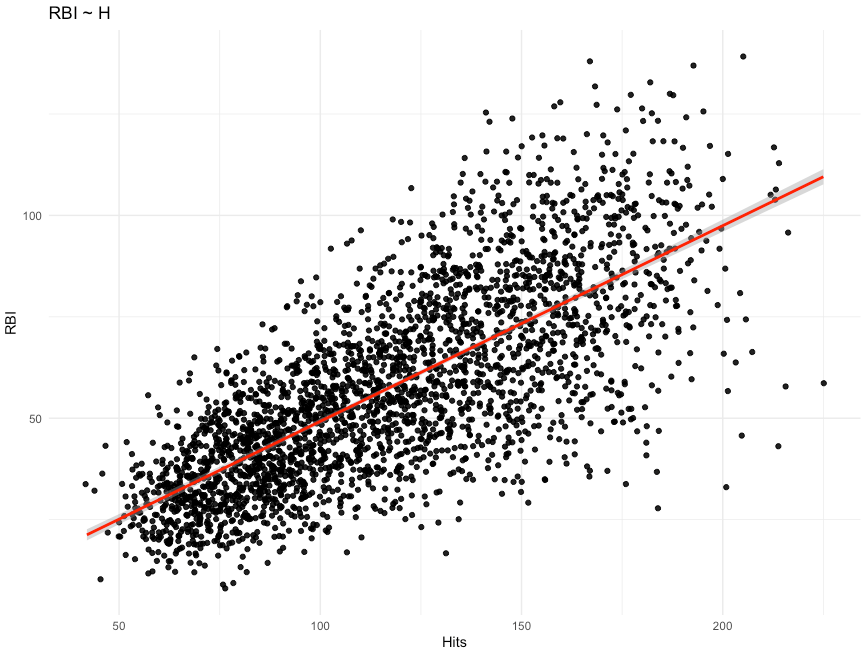
Notice how narrow the 95% confidence interval is around the regression line. The lightly grey shaded region is barely visible because the interval is so tight.
While plotting the data like this is simple, it might help us understand what is going on better if we constructed our own data frame of predictions and intervals and then overlaid those onto the original data set.
We begin by creating a data frame that has a single column, H, representing the range of hits observed in our data set. We then can create predictions and our 95% Prediction and Confidence Intervals across the vector of hits data that we just created.
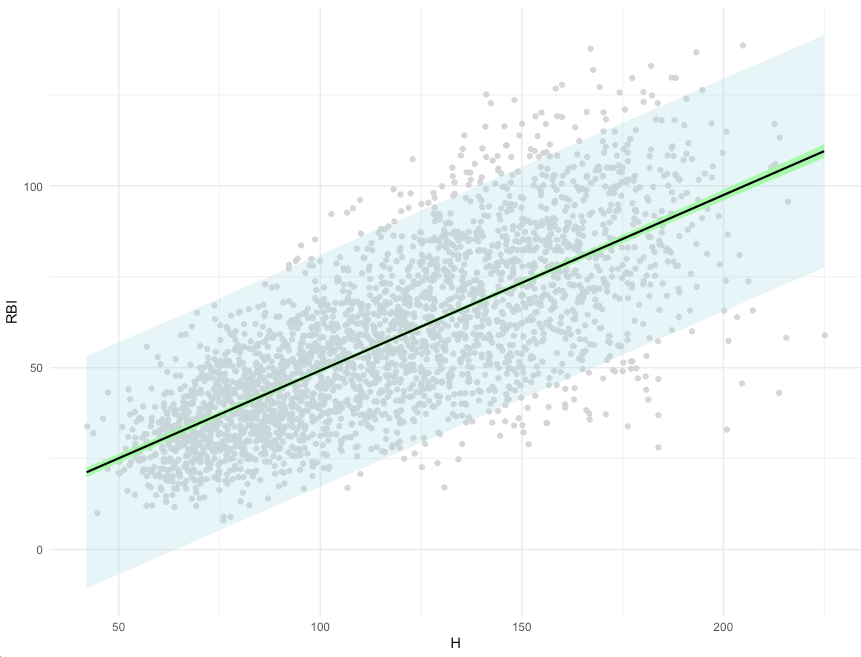
Similar to our first plot, we see that the 95% confidence interval (green) is very tight to the regression line (black). Also, the prediction interval (light blue) is substantially larger than the confidence interval across the entire range of values.
A Bayesian Perspective
We now take a Bayesian approach to constructing intervals. First, we need to specify our regression model. To do so I will be using the rethinking package which serves as a supplement to Richard McElreath’s brilliant textbook, Statistical Rethinking: A Bayesian Course with Examples in R and Stan.
To create our Bayesian model we will need to specify a few priors. Before specifying these, however, I am going to mean center the independent variable, Hits, and create a new variable called hits_c. Doing so helps with interpretation of the model output and it should be noted that the intercept will now reflect the expected value of RBIs when there is an average number of hits (which would be hits_c = 0).
For my priors:
- Intercept = N(70, 25) — represents my prior belief of the number of RBI’s when a batter has an average number of hits.
- Beta Coefficient = N(0, 20) — This prior represent the amount of change in RBI for a unit of change in a batter’s hits relative to the average number of hits for the population.
- Sigma = Unif(0, 20) — this represents my prior for the model standard error.
library(rethinking)
## What is the average number of hits?
mean(df$H)
## Mean center hits
df <- df %>%
mutate(hits_c = H - mean(H))
## Fit the linear model and specify the priors
rbi_bayes <- map(
alist(
RBI ~ dnorm(mu, sigma), # dependent variable (RBI)
mu <- a + b*hits_c, # linear model regressing RBI on H
a ~ dnorm(70, 25), # prior for the intercept
b ~ dnorm(0, 20), # prior for the beta coefficient
sigma ~ dunif(0, 20)), # prior for the model standard error
data = df)
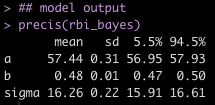
## model output
precis(rbi_bayes)
Predict the number of RBI for our batter with 100 hits
The nice part of the Bayesian framework is that we can sample from the posterior distribution of our model and build simulations.
We start by extracting samples from our model fit. We can also then plot these samples and get a clearer understanding of the certainty we have around our model output.
coef_sample <-extract.samples(rbi_bayes)
coef_sample[1:10, ]
## plot the beta coefficient
hist(coef_sample$b,
main = "Posterior Samples of Hits Centered Coefficient\nFrom Bayesian Model",
xlab = "Hits Centered Coefficient")
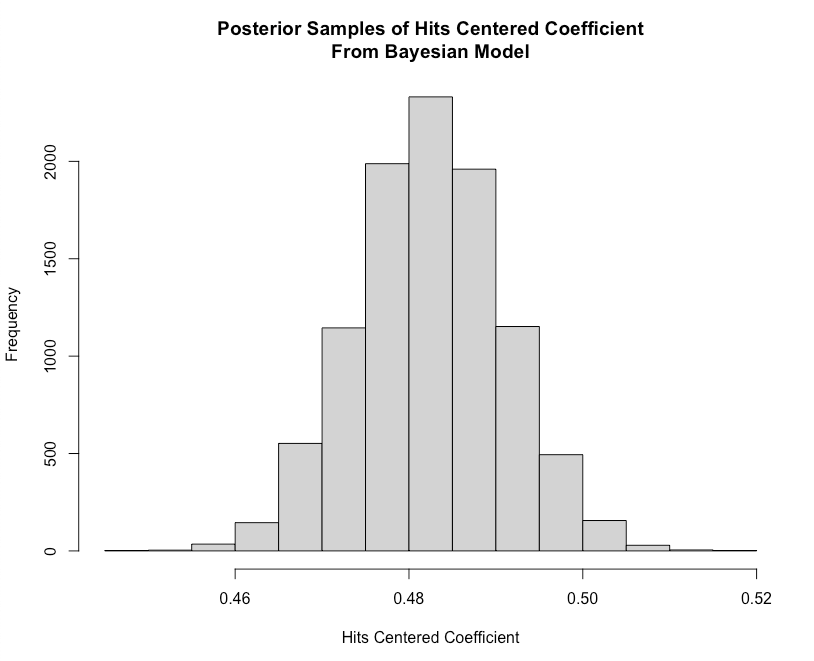
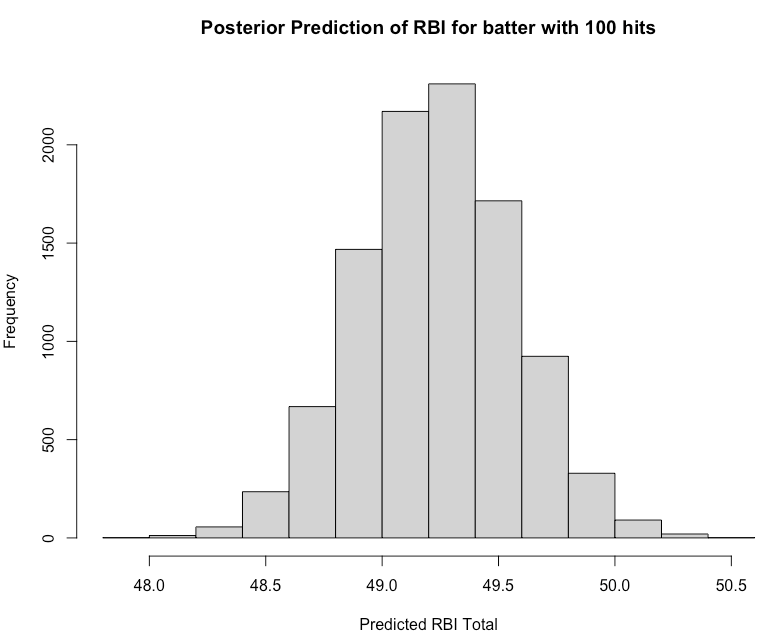
Our batter had 100 hits. Remember, since our model independent variable is now centered to the population mean we will need to center the batter’s 100 hits to that value prior to using our model to predict the number of RBI’s we’d expect. We will then plot the full sample of the predicted number of RBI’s to reflect our uncertainty around the batter’s performance.
## Hypothetical batter with 100 hits
hits <- 100
hits_centered <- hits - mean(df$H)
## Predict RBI total from the model
rbi_sample <- coef_sample$a + coef_sample$b * hits_centered
## Plot the posterior sample
hist(rbi_sample,
main = "Posterior Prediction of RBI for batter with 100 hits",
xlab = "Predicted RBI Total")
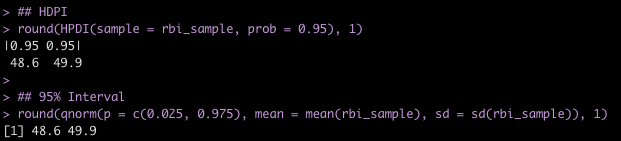
Highest Density Posterior Interval (HDPI)
We now create an interval around the RBI samples. Bayesians often discuss intervals around a point estimate under various different names (e.g., Credible Intervals, Quantile Intervals, Highest Density Posterior Intervals, etc.). Here, we will use Richard McElreath’s HDPI() function to calculate the highest density posterior interval. I’ll also use qnorm() to show how to obtain the 95% interval of the sample.
## HDPI round(HPDI(sample = rbi_sample, prob = 0.95), 1) ## 95% Interval round(qnorm(p = c(0.025, 0.975), mean = mean(rbi_sample), sd = sd(rbi_sample)), 1)
Prediction Interval
We can also use the samples to create a prediction interval for a single batter (remember, this will be larger than the confidence interval). To do so, we first simulate from our Bayesian model for the number of hits the batter had (100) and center that to the population average for hits.
## simulate from the posterior rbi_sim <- sim(rbi_bayes, data = data.frame(hits_c = hits_centered)) ## 95% Prediction interval PI(rbi_sim, prob = 0.95)

Plotting Intervals Across All of the Data
Finally, we will plot our confidence intervals and prediction intervals across the range of our entire data. We will need to make sure and center the vector of hits that we create to the mean of hits for our original data set.
## Create a vector of hits
hit_df <- data.frame(H = seq(from = min(df$H), to = max(df$H), by = 1))
## Center the hits to the average number of hits in the original data
hit_df <- hit_df %>%
mutate(hits_c = H - mean(df$H))
## Use link() to calculate a mean value across all simulated values from the posterior distribution of the model
mus <- link(rbi_bayes, data = hit_df)
## get the average and highest density interval from our mus
mu_avg <- apply(X = mus, MARGIN = 2, FUN = mean)
mu_hdpi <- apply(mus, MARGIN = 2, FUN = HPDI, prob = 0.95)
## simulate from the posterior across our vector of centered hits
sim_rbi_range <- sim(rbi_bayes, data = hit_df)
## calculate the prediction interval over this simulation
rbi_pi <- apply(sim_rbi_range, 2, PI, prob = 0.95)
## create a plot of confidence intervals and prediction intervals
plot(df$H, df$RBI, pch = 19,
col = "light grey",
main = "RBI ~ H",
xlab = "Hits",
ylab = "RBI")
shade(rbi_pi, hit_df$H, col = col.alpha("light blue", 0.5))
shade(mu_hdpi, hit_df$H, col = "green")
lines(hit_df$H, mu_avg, col = "red", lwd = 3)
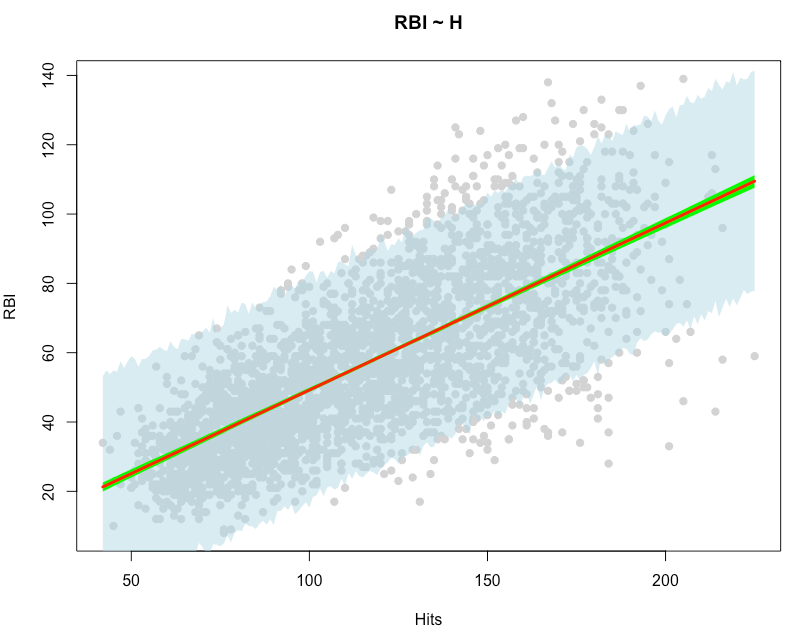
Similar to our frequentist intervals, we see that the 95% HDPI interval (green) is very narrow and close to the regression line (red). We also see that the 95% prediction interval (light blue) is much larger than the HDPI, as it is accounting for more uncertainty when attempting to make a prediction for a single individual within the population.
Wrapping Up
When making predictions it is always important to reflect the uncertainty that you have around your model’s outcome. Confidence intervals and prediction intervals are two ways to present your uncertainty for two different objectives. Confidence intervals say something about the uncertainty for the population average while prediction intervals attempt to provide uncertainty for an individual within the population. As a consequence, prediction intervals end up being wider than confidence intervals. The approach to sharing your model’s uncertainty can be done from either a frequentist or Bayesian perspective.
To access all of the code for this blog article, CLICK HERE.