
I was reading a paper this weekend and the researchers used a mixed model to for their data given that they were dealing with repeated measures of individuals and teams. Mixed models have become common in sport science research and I’ve written about them a few times in this blog:
- Mixed Models in Sports Science: Frequentist & Bayesian
- Plotting Mixed Model Outputs
- Making Predictions from a Mixed Model using R
As I was reading the paper I was wondering, because it wasn’t specified in the methods section, if the researchers had given any thought to whether their random effects were crossed or nested. Then I thought, maybe people aren’t thinking about this and perhaps a short blog article with an example would be useful. So here we are…
For brevity, I’ll only present short snippets of code in the blog article. The entire code is available on my Github Page.
Data
We need to simulate some data to work with. To keep things simple, we will create a data set of a league that has 6 teams and 60 players. Each player will have a player value metric, the outcome of interest, for every team they played on during the season.
suppressPackageStartupMessages({
suppressMessages({
suppressWarnings({
library(tidyverse)
library(lme4)
library(arm)
})
})
})
theme_set(theme_bw())
set.seed(225544)
teams <- sample(c("Sharks", "Bears", "Turtles", "Bisons", "Jaguars", "Pythons"), size = 60, replace = TRUE)
players <- as.factor(sample(1:60, size = 60, replace = TRUE))
intercept <- 50
team_effect <- case_when(teams == "Sharks" ~ rnorm(1, mean = 0, sd = 7),
teams == "Bears" ~ rnorm(1, mean = 0, sd = 2),
teams == "Turtles" ~ rnorm(1, mean = 0, sd = 1),
teams == "Bisons" ~ rnorm(1, mean = 0, sd = 13),
teams == "Jaguars" ~ rnorm(1, mean = 0, sd = 5),
teams == "Pythons" ~ rnorm(1, mean = 0, sd = 3))
player_effect <- rnorm(length(levels(players)), mean = 0, sd = 10)
random_noise <- 2
dat <- data.frame( team = teams, player_id = players ) %>%
mutate(
mu = intercept + team_effect + player_effect[players],
player_value = round(mu + rnorm(n(), mean = 0, sd = random_noise), 1)
) %>%
dplyr::select(-mu)
dat %>%
head()

EDA
How many unique players were on each team during the season?

Which players played on multiple teams?

Team Summary Stats

Crossed vs Nested Effects
We have 14 players that played on multiple teams (Player 11 ended up playing for all 6 teams!) and, as a consequence, different teams had different numbers of individual players. For example, the Bears had 13 different players while the Pythons had 6 different players. This small detail is important to consider with respect to our random effects because crossed and nested effects behave differently with respect to how they partition variance.
When constructing mixed models we usually have a data hierarchy where observations are grouped or nested within specific categories. When the observations are nested the observations are exclusive to specific groups. Some examples:
- Classes are nested within schools but classes in one school cannot also be grouped within a different school.
- Athletes competing in the Olympics are nested within their respective countries but an individual cannot compete for two different countries in the same Olympic Games.
By contrast, crossed effects can occur when observations move between groups during the same study/observation period. A few examples of crossed effects are:
- A student might start the year at one school and then move half way through the semester and attend a different school.
- Players in team sport might be traded mid-season and play for different teams.
- In a study where the experimental and placebo groups contain both male and female participants, we would have crossed random effects to account for sex being in both groups.
- Looking at sports teams, we may be analyzing the behavior of position groups on different teams. The position groups are the same for each team (e.g., Forwards, Guards, and Centers on Basketball teams) so the model has crossed effects.
To help solidify this concept a bit more, I’ve created the below drawing.
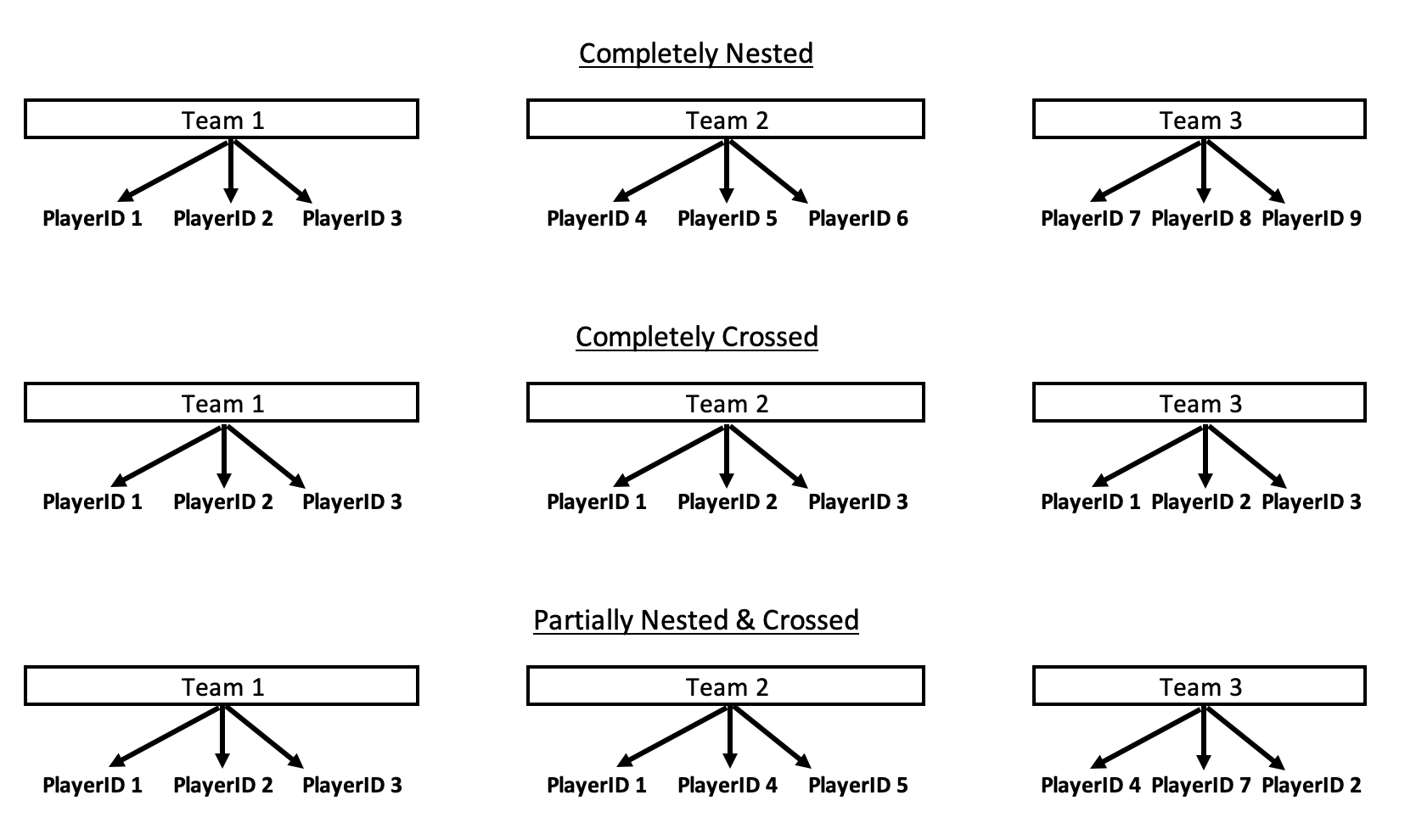
We see that in the Completely Nested example there are individual players that only player for their respective teams. Contrast that to the Completely Crossed example, where every player ends up playing on each team. This would, obviously, be an incredibly weird scenario and not one we’d see in sport but probably one that you’d see in researched where there is a crossover of treatments. Finally, the Partially Nested & Crossed example has a few players playing for multiple teams (for example, Player 1 played for both Team 1 and Team 2) and some players that stay with a single team during the season. This version is the one that we most frequently encounter in team sport.
Now that we have a general understanding of the difference between crossed and random effects, let’s see how this looks when we build a model on our simulated data and (most importantly) let’s see how specifying the model to have crossed or nested random effects changes the model output.
Model Examples
Crossed
Since we commonly deal with crossed (or partially nested/crossed) data in team sport, I’ll start with modeling the data to have crossed random effects. As a side note, most of the time when I look at people’s models in sport science they are creating the model structure like this, by default.
We will build random intercept model (since we didn’t simulate any fixed effects) and allow a separate intercept variance for both team and player_id, keeping in mind that this specifies that there are players who are potentially playing on different teams (crossed observations) across the season.
lme_crossed <- lmer(player_value ~ 1 + (1|team) + (1|player_id), data = dat)
Nested
Next, we fit the random intercept model but this time we treat our random effects of player_id and team as nested. That is to say that we are allowing the players to be nested within their respective teams. To review, this means that we are treating this data as if each player only played on a single team during the season and never changed teams.
lme_nested <- lmer(player_value ~ 1 + (1|team) + (1|team:player_id), data = dat)
Comparing the two models

First, we notice that the fixed effects are slightly different between the two models, but the difference in small in this simulated data.
The random effects look very different between the two model structures. In the crossed effects model we get two different random effects — one for the player_id and one for the team. However, in the nested effects model we have a random effect for team but then we have a random effect for player_id nested within each team. So, in the nested model a player that played for multiple teams will have different random intercept for each of the teams they were nested in. Both models, of course, also have a residual in the random effects, however the values are very different.
Let’s compile the random effects side-by-side to get a better appreciation for the differences. We will start with the `team` random effect since it is present in both models.

There are pretty stark differences between the random intercepts of the nested and crossed models! Recall from our EDA that the Bears had the highest average value of all the teams and they also had the fewest number of different players (5).
The player random effects get a little wonky because players who played for multiple teams will end up having different random effects depending on which team we nested them in. Conversely, in the crossed model we get one random effect estimate per player.
To join the random effects from both models we have to do a bit of work on the nested model to extract the info. (NOTE: Since the table is really long I’ll only show the first 10 rows here but you can got to the Github page to see the full output.)

Joining the two model random effects on player_id we see that player’s have some very different random effects between the two models. In particular, players that played on different teams can differ greatly between the models.
For example, let’s look at Player 21.

In the crossed model we find that Player 21 has a random intercept that is 1.6 points below league average (the fixed effect intercept). However, in the nested model, when Player 21 was on the Bears he was 1.15 points above the population intercept and 0.74 points below the population intercept when he was on the Turtles. This is partially due to the team effect, where the the Bears were the best team in the league (highest average value) and the Turtles were the worst team in the league (lowest average value).
Wrapping Up
Hopefully this tutorial provided a brief, but useful, overview of crossed versus random effects during mixed model construction. While most people seem to gravitate towards crossed effects by default there may be times where nested effects are indeed required for the structure of the data. As the example shows, how we specify the model can dramatically change the outputs and thus the inference that we can derive from these outputs.
To access the full code please see the Github page.





























