
When looking at sports statistics it’s important to keep in mind that performance is a blend of both skill and luck. As such, recognizing that all athletes exhibit some level of regression to the mean helps us put into perspective that observed performance is not necessarily where that individual’s true performance lies. For example, we wouldn’t believe that a baseball player who starts the MLB season going 6 for 10 has a true .600 batting average that they will carry throughout the season. Eventually, they will regress back down to something more normal (more average). Conversely, if a player starts the season 1 for 10 we would expect them to eventually move back up to something more normal.
A goal in sports analytics is to try and estimate the true performance of a player given some observed data. One of my favorite papers on this topic is from Efron and Morris (1977), Stein’s Paradox in Statistics. The paper discusses ways of using observed outcomes to make future forecasts using the James-Stein Estimator and then a Bayes Estimation approach.
Using 2019 MLB data, I’ve put together some R code to walk through the methods proposed in the paper.
Getting Data
First, we need to load Bill Petti’s baseballr package, which is a handy package for scraping MLB data. We will also load the ggplot2 package for data visualizations
library(baseballr) library(ggplot2)
The aim of this analysis will be to look at hitting performance (batting average) over the first 30 days of the 2019 MLB season, make a forecast of the player’s true batting average, based on the observations of those first 30 days, and then test that forecast on the next 30 days.
We will obtain two data sets, a first 30 days data set and a second 30 days data set.
### Get first 30 days of 2019 MLB and Second 30 days dat_first30 <- daily_batter_bref(t1 = "2019-03-28", t2 = "2019-04-28") dat_second30 <- daily_batter_bref(t1 = "2019-04-29", t2 = "2019-05-29") ## Explore the data frames head(dat_first30) head(dat_second30) dim(dat_first30) # 595 x 29 dim(dat_second30) # 611 x 29
Evaluating The Data
Let’s now reduce the two data frame’s down to the columns we need (Name, AB, and BA).
dat_first30 <- dat_first30[, c("Name", "AB", "BA")]
dat_second30 <- dat_second30[, c("Name", "AB", "BA")]
Let’s look at the number of observations (AB) we see for the players in the two data sets.
quantile(dat_first30$AB) quantile(dat_second30$AB)

par(mfrow = c(1,2)) hist(dat_first30$AB, col = "grey", main = "First 30 AB") rug(dat_first30$AB, col = "red", lwd = 2) hist(dat_second30$AB, col = "grey", main = "Second 30 AB") rug(dat_second30$AB, col = "red", lwd = 2)
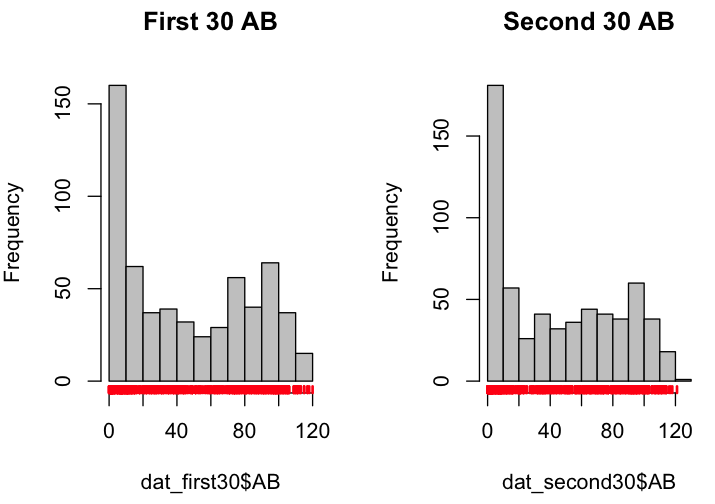
We see a considerable right skew in the data with a large number of players observing a small amount of at bats over the first 30 days and a few players observing a large number observations (the everyday players).
Let’s see what Batting Average looks like.
quantile(dat_first30$BA, na.rm = T) quantile(dat_second30$BA, na.rm = T)

par(mfrow = c(1,2)) hist(dat_first30$BA, col = "grey", main = "First 30 BA") rug(dat_first30$BA, col = "red", lwd = 2) hist(dat_second30$BA, col = "grey", main = "Second 30 BA") rug(dat_second30$BA, col = "red", lwd = 2)

We see the median batting average for MLB players over the 60 days ranges from .224, in the first 30 days, to .234, in the second 30 days. We also see some players with a batting average of 1.0, which is probably because they batted only one time and got a hit. We also see that there are a bunch of players with a batting average of 0.
This broad range of at bats and batting average values is actually going to be interesting when we attempt to forecast future performance as small sample sizes make it difficult to have faith in a player’s true ability. This is one area in which the James-Stein Estimator and Bayes Estimation approaches may be useful, as they allow for shrinkage of the observed batting averages towards the mean. In this way, the forecast isn’t too overly confident about the player who went 6 for 10 and it isn’t too under confident about the player who went 1 for 10. Additionally, for the player who never got an at bat, the forecast will suggest that the player is an average player until future data/observations can be gathered to prove otherwise.
Estimating Performance
We will use 3 approaches to forecast performance in the second 30 days:
- Use the batting average of the player in the first 30 days and assume that the next 30 days would be similar. This will server as our benchmark for which the other two approaches need to improve upon if we are to use them. Note, however, that this approach doesn’t help us at all for players who had 0 at bats.
- Use a James-Stein Estimator to forecast the second 30 days by taking the observed batting averages and applying a level of shrinkage to account for some regression to the mean.
- Account for regression to the mean by using some sort of prior assumption of the batting average mean and standard deviation of MLB players. This is a type of Bayes approach to handling the problem and is discussed in the last section of Effron and Moriss’s article.
Before we start making our forecasts, I’m going to take a random sample of 50 players from the first 30 days data set. This will allow us to work with a subset of the data for the sake of the example. Additionally, rather than cleaning up the data or setting an inclusion criteria based on number of at bats, by taking a random sample, I’ll get a good mix of players that had no at bats, very little at bats, an average number of at bats, and a large number of at bats. This will allow us to see how well the three forecast approaches handle a large variability in observations. (Technical Note: If you are going to follow along with the r-script below, make sure you use the same set.seed() as I do to ensure reproducibility).
## Get a sample of 50 players from the first 30 set.seed(1657) N <- nrow(dat_first30) samp_size <- 50 samp <- sample(x = N, size = samp_size, replace = F) first30_samp <- dat_first30[samp, ] head(first30_samp)
We need to locate these same players in the second 30 days data set so that we can test our forecasts.
## Find the same players in the second 30 days data set second30_samp <- subset(dat_second30, Name %in% unique(first30_samp$Name)) nrow(second30_samp) # 37
Only 37 players from the first set of players (the initial 50) are available in the second 30 days. This could be due to a number of reasons such as injury, getting sent down to triple A, getting benched for a player that was performing better, etc. In any event, we will work with these 37 players from here on out. So, we need to go into the sample from the first 30 days and find those players. Then we merge the two sample sets together
## Subset out the 37 players in the first 30 days sample set first30_samp <- subset(first30_samp, Name %in% second30_samp$Name) nrow(first30_samp) # 37 ## Merge the two samples together df <- merge(first30_samp, second30_samp, by = "Name") head(df)
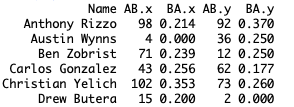
The first 30 days are denoted as AB.x and BA.x while the second are AB.y and BA.y.
First 30 Day Batting Average to Forecast Second 30 Day Batting Average
Using the two columns, BA.x and BA.y, we can subtract one from the other to obtain the difference in our forecast had we simply assumed the first 30 day’s performance (BA.x) would be similar to the second (BA.y). From there, we can calculate the mean absolute error (MAE) and the root mean square error (RMSE), which we will use to compare the other two methods.
## Difference between first 30 day BA and second 30 day BA df$Proj_Diff_Avg <- with(df, BA.x - BA.y) mae <- mean(abs(df$Proj_Diff_Avg), na.rm = T) rmse <- sqrt(mean(df$Proj_Diff_Avg^2, na.rm = T))
Using the James-Stein Estimator
The forumla for the James-Stein Estimator is as follows:
JS = group_mean + C(obs_BA – group_mean)
Where:
- group_mean = the average of all players in the first 30 days
- obs_BA = the observed batting average for an individual player in the first 30 days
- C = a constant that represents the shrinkage factor. C is calculated as:
- C = 1 – ((k – 3)*σ2)/(Σ(y – ŷ)2)
- k = the number of unknown means we are trying to forecast (in this case the sample size of our first 30 days)
- σ2 = the group variance observed during the first 30 days
- (Σ(y – ŷ)2) = the sum of the squared differences between each player’s observed batting average and the group average during the first 30 days
- C = 1 – ((k – 3)*σ2)/(Σ(y – ŷ)2)
First we will calculate our group mean, group SD, and squared differences from the first 30 day sample.
# Calculate grand mean and sd group_mean <- round(mean(df$BA.x, na.rm = T), 3) group_mean # .214 group_sd <- round(sd(df$BA.x, na.rm = T), 3) group_sd # .114 ## Calculate sum of squared differences from the group average sq.diff <- sum((df$BA.x - group_mean)^2) sq.diff # .467
Next we calculate our shrinkage factor, C.
## Calculate shirinkage factor
k <- nrow(df) c <- 1 - ((k - 3) * group_sd^2) / sq.diff c # .053
Now we are ready to make a forecast of batting average for the second 30 days using the James-Stein Estimator and calculate the MAE and RMSE.
df$JS <- group_mean + c*(df$BA.x - group_mean) df$Proj_Diff_JS <- with(df, JS - BA.y) mae_JS <- mean(abs(df$Proj_Diff_JS), na.rm = T) rmse_JS <- sqrt(mean(df$Proj_Diff_JS^2, na.rm = T))
Using a Prior Assumption for MLB Batting Average
In this example, the prior batting average I’m going to use will be the mean and standard deviation from the entire first 30 day data set (the original data set, not the sample). I could, of course, use historic data to build my prior assumption but I figured I’ll just start with this approach since I have the data readily accessible.
# Get a prior for BA prior_BA_avg <- mean(dat_first30$BA, na.rm = T) prior_BA_sd <- sd(dat_first30$BA, na.rm = T) prior_BA_avg # .203 prior_BA_sd # .136
For our Bayes Estimator, we will use the following approach:
BE = prior_BA_avg + prior_BA_sd(obs_BA – prior_BA_avg)
df$BE <- prior_BA_avg + prior_BA_sd*(df$BA.x - prior_BA_avg) mae_BE <- mean(abs(df$Proj_Diff_BE), na.rm = T) rmse_BE <- sqrt(mean(df$Proj_Diff_BE^2, na.rm = T))
Looking at Our Forecasts
Let’s put the MAE and RMSE of our 3 approaches into a data frame so we can see how they performed.
Comparisons <- c("First30_Avg", "James_Stein", "Bayes")
mae_grp <- c(mae_avg, mae_JS, mae_BE)
rmse_grp <- c(rmse_avg, rmse_JS, rmse_BE)
model_comps <- data.frame(Comparisons, MAE = mae_grp, RMSE = rmse_grp)
model_comps[order(model_comps$RMSE), ]

It looks like the lowest RMSE is the Bayes Estimator. The James-Stein Estimator is not far behind. Both approaches out performed just using the player’s first 30 day average as a naive forecast for future performance.
We can visualizes the differences in our projections for the three approaches as well.
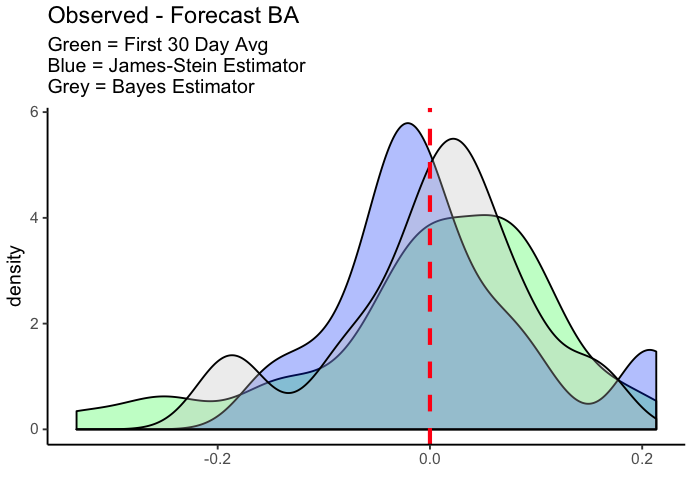
We can see that making projections based off of first 30 day average (green) is wildly spread out and the mean value appears to over project a player’s true ability (the peak is greater than 0, the dashed red line). Conversly, the James-Stein Estimator (blue) has a pretty strong peak that is just below 0, meaning it may be under projecting players and pulling some players down too far towards the group average. Finally, the Bayes Estimator (grey) resides in the middle of the two projections with its peak just above 0.
The last thing I’ll do is put some confidence intervals around the Bayes Estimator for each player and take a look at how the sample size influences the forecast and where the observed batting average during the second 30 days was in relationship to that forecast.
df$Bayes_SE <- with(df, sqrt((bayes * (1-bayes))/AB.x)) df$Low_CI <- df$bayes - 1.96*df$Bayes_SE df$High_CI <- df$bayes + 1.96*df$Bayes_SE
We can then plot the results. (Technical Note: To keep the plot from being too busy, I used only plot the first 15 rows of the data set).
ggplot(df[1:15, ], aes(x = reorder(Name, AB.x), y = bayes)) +
geom_point(color = "blue") +
geom_point(aes(y = BA.y), color = "red") +
geom_errorbar(aes(ymin = Low_CI, ymax = High_CI), width = 0) +
geom_text(aes(label = paste(AB.x, "ABs", sep = " ")), vjust = -1, size = 3) +
geom_hline(aes(yintercept = 0), linetype = "dashed") +
coord_flip() +
theme_classic() +
ggtitle("Bayes Estimator",
subtitle = "Blue = Bayes Estimation \nRed = Observed BA during second 30 day \nLabeled ABs = Individual Sample Size the Estimation was built on (First 30 days ABs)")

The at bats labelled in the plot are specific to the first 30 days of data, as they represent the number of observations for each individual that the forecast was built on. We can see that when we have more observations, the forecast does better at identifying the player’s true performance based on their first 30 days. Rizzo and Igelsias were the two that really beat their forecast in the second 30 days of the 2019 season (Rizzo in particular). The guys at the bottom (Butera, Wynns, Duplantier, and Fedde) are much harder to forecast given they had such few observations in the first 30 days. In the second 30 days, Duplantier only had 1 AB while Butera and Fedde only had 2.
Wrapping Up
The aim of this post was to work through the approaches to forecasting performance used in a 1977 paper from Efron and Morris. Dealing with small samples is a problem in sport and what we saw was that if we naively just use the average performance of a player during those small number of observations we may be missing the boat on their underlying true potential due to regression to the mean. As such, things like the James-Stein Estimator or Bayes Estimator can help us obtain better estimates by using a prior assumption about the average player in the population.
There are other ways to handle this problem, of course. For example, an Empirical Bayes Approach could be used by assuming a beta distribution for our data and making our forecasts from there. Finally, alternative approaches to modeling could account for different variables that might influence a player during the first 30 days (injury, park factors, strength of opponent, etc). However, the simple approaches presented by Efron and Morris are a nice start.
References
- Efron, B., Morris, CN. (1977). Stein’s Paradox in Statistics. Scientific American, 236(5): 119-127.