
Intro
Evaluating whether an athlete has or has not improved in some key performance indicator is critical to understanding the success of a prescribed training or rehabilitation program. In the applied setting, practitioners are faced with N = 1 decisions as they are training or rehabilitating individual athletes, each of whom is unique in their own way. As such, tests that allow practitioners to understand these individual improvements are imperative to quantifying the training process.
The analysis of athlete testing data first requires an understanding of what the test is measuring (whether it is valid or not) and the amount of noise/error within the test (whether the test is reliable or not). Tests that are overly noisy make it challenging for practitioners to reliably know whether or not changes exhibited by the athlete are due to real performance improvement, measurement error (e.g., issues with the test itself) or biological variation. Approaches to analyzing test-retest data to evaluate typical error measurement (TEM) and smallest worthwhile change (SWC) have been previously discussed by authors such as Hopkins1, Swinton2, and Turner3. Recently, my friend and colleague, Shaun McLaren, wrote a blog post on understanding statistics when interpreting individualized testing data. Such approaches are important in the applied setting as the last thing a practitioner or clinician wants to do is report inaccurate information regarding an athlete’s current physical state to the coach or management. From a medical/return-to-play standpoint, such information is important for ensuring that the athlete is making progress and meeting certain benchmarks to ensure a safe return from injury.
The analytical approaches Shaun discussed are relatively easy to perform, and interested readers can download Excel sheets that will automatically calculate these measures and only require the practitioner to provide test-retest data. My aim in this blog post is to walk though similar statistical approaches using the coding language R and build a function that will automatically calculate these metrics once the practitioner provides their data (analysis for this blog post was built of of the methods proposed by Swinton and Colleagues2, who provide similar methods in excel on the article’s webpage).
Simulating Data
First, we need to create some data to play with. I’ll simulate two different data sets:
-
-
- Data Set 1: Test-Retest Data
- This data set will serve as our test-retest trial data. We will use this data set to calculate measures to get a sense for how noisy the test is and calculate measures such as TEM and SWC. For example, let’s say that this test-retest trial is something like a simple vertical jump test. We want to have the athletes perform the test, take a rest period, and then perform the test again. We will then calculate how much error there is in the test.
- Data Set 2: Training Intervention Data
- Once we’ve established TEM and SWC, we will simulate a second data set that represents a group of athletes performing an experimental training intervention (strength training only) and another group of athletes performing a control condition (endurance training only). We will write a function to evaluate the responses from this data to understand how successful the intervention truly was.
- Data Set 1: Test-Retest Data
-
Test-Retest Data Simulation
Our test-retest data will be a simulation of a vertical jump test for 20 athletes.
### Load packages
library(dplyr)
library(ggplot2)
library(reshape)
### Simulate data
set.seed(2018)
subject <- LETTERS[1:20]
group <- rep(c("experimental", "control"), each = 10)
test <- c(round(rnorm(n = 10, mean = 25, sd = 4),1), round(rnorm(n = 10, mean = 25, sd = 3), 1))
retest <- c(round(rnorm(n = 10, mean = 25, sd = 5),1), round(rnorm(n = 10, mean = 24, sd = 4), 1))
reliability.data <- data.frame(subject, test, retest)
head(reliability.data)
subject test retest
1 A 23.3 31.3
2 B 18.8 26.3
3 C 24.7 26.3
4 D 26.1 33.9
5 E 31.9 18.9
6 F 23.9 23.8
Two metrics we are interested in obtaining from the data are TEM and SWC.
- Typical error of measurement (TEM) is calculated as the standard deviation of the difference between test-retest scores divided by the square root of 2.
- TEM = sd(Difference) / sqrt(2)
- Smallest worthwhile change (SWC) is calculated as the standard deviation of Test 1 multiplied by an effect size of interest. Hopkins and Batterham4 recommend this effect size to be 0.2, as 0.2 represents the “smallest worthwhile effect” according to Jacob Cohen.
- SWC = sd(Test1 Scores) * magnitude threshold
Note on the magnitude threshold: With a very homogeneous group of athletes the standard deviation, and ensuing SWC, can be very small, perhaps so small that it is almost meaningless (Buchheit5) . However, I encourage practitioners to determine the effect size of interest based on the magnitude of change that they feel would be meaningful to worry about or meaningful to report to a coach. This might come down to the type of test being performed or the age/experience of the athlete. I don’t think it is as easy as simple saying “0.2 is always our benchmark.” Sometimes we may want to have a larger magnitude of interest (perhaps 0.8, 1.0, or 1.2). To be consistent with the scientific literature, I’ll use 0.2 in for this example, however, in the test-retest function below, I allow the practitioner to choose the magnitude threshold that is most important to them.
######### Test-Retest Function ######################
#####################################################
Test_Retest <- function(test1, test2, magnitude.threshold){
require(dplyr)
# combine the vectors into a dataset
dataset <- data.frame(test1, test2)
# calculate difference
dataset$Diff <- with(dataset, test2-test1)
# Calculate Mean & SD
stats <- as.data.frame(dataset %>%
summarize(PreTest.Mean = round(mean(test1, na.rm =T),2),
PreTest.SD = round(sd(test1, na.rm = T),2),
PostTest.Mean = round(mean(test2, na.rm = T), 2),
PostTest.SD = round(sd(test2, na.rm = T), 2),
Mean.Difference = round(mean(Diff, na.rm = T), 2),
SD.Difference = round(sd(Diff, na.rm = T), 2)))
# Calculate TEM
TEM <- sd(dataset$Diff, na.rm = 2)/sqrt(2)
# Calculate SWC
swc <- magnitude.threshold*sd(test1)
# Function output
list(SummaryStats = stats, TEM = round(TEM,2), SWC = round(swc, 3))
}
With the function loaded, we can now supply it with the data from our simulated test-retest trial. All that is required are three inputs:
- A vector representing the the scores for test 1.
- A vector representing the scores for test 2 (the re-test).
- The magnitude of threshold of interest. (Again, in this example I’ll use 0.2, to represent the smallest worthwhile change. Feel free to change this to a different magnitude threshold, such as 0.8 or 1.2, and see how it effects the results.)
test.retest.results <- Test_Retest(test1 = reliability.data$test, test2 = reliability.data$retest, magnitude.threshold = 0.2) test.retest.results

Looking at the output, we see that the results are returned as a list with three elements:
- Summary statistics of both tests and the difference between tests
- The TEM
- The SWC
This type of list format is useful if you want to call specific parts of the analysis. For example, if I need the TEM to be included downstream, in a later analysis, I can simply call it by typing:
test.retest.results$TEM [1] 4.83
One thing we may notice from the output of our function is that the error for this test is rather large, relative to the SWC. This could potentially be an issue when attempting to interpret future results for this test, given the error is so large. In this case, we may want to go back to the drawing board with our test and try to figure out a way to minimize the test error (or potentially consider using a different test). Alternatively, using this test would mean that we need to have a rather large change in the athlete’s performance to be certain that improvement the athlete had was “real.”
Training Intervention Simulation Data
The training data that we’ll simulate will have baseline vertical jump scores and follow-up vertical jump scores at 8 weeks. Group 1 will only perform strength training while Group 2 will only perform endurance training.
### Simulate data
set.seed(2018)
subject <- LETTERS[1:20]
group <- rep(c("experimental", "control"), each = 10)
baseline <- c(round(rnorm(n = 10, mean = 24, sd = 3),1), round(rnorm(n = 10, mean = 24, sd = 3), 1))
post.intervention <- c(round(baseline[1:10] + rnorm(n = 10, mean = 8, sd = 5), 1), round(rnorm(n = 10, mean = 27, sd = 5), 1))
study.data <- data.frame(subject, group, baseline, post.intervention)
head(study.data)
subject group baseline post.intervention
1 A experimental 22.9 35.1
2 B experimental 20.1 31.0
3 C experimental 21.4 30.3
4 D experimental 27.2 33.0
5 E experimental 23.6 31.2
6 F experimental 27.1 30.5
tail(study.data)
subject group baseline post.intervention
15 O control 23.4 30.4
16 P control 25.4 24.5
17 Q control 21.2 17.7
18 R control 32.2 30.7
19 S control 25.0 26.6
20 T control 22.1 32.4
Next, we create a function called outcome, which takes the following eight inputs:
- A vector of baseline scores
- A vector of post-test scores (follow-up scores)
- A vector denoting which subjects belong to each of the groups
- A vector of subject IDs
- The TEM established from our test-retest trial above
- The SWC established from our test-retest trial above
- The number of samples in our test-retest trial (Reliability.N = 20)
- The confidence interval we are interested in. For this example I’ll use 95%. However, feel free to change this value and see how it influences the results
outcome <- function(baseline.test, post.test, groups, subject.IDs, TEM, SWC, Reliability.N, Conf.Level){
# Combine the vecotors into a data set
df <- data.frame(subject.IDs, groups, baseline.test, post.test)
# True Baseline Score Calculation
df$LowCI.baseline.true <- round(baseline.test - qt(p = (1-Conf.Level)/2, df = Reliability.N - 1, lower.tail = F)*TEM, 2)
df$HighCI.baseline.true <- round(baseline.test + qt(p = (1-Conf.Level)/2, df = Reliability.N - 1, lower.tail = F)*TEM, 2)
# create a difference score
df$Pre.Post.Diff <- with(df, post.test - baseline.test)
# create confidence intervals around the difference score
df$LowCI.Diff <- round(df$Pre.Post.Diff - qt(p = (1-Conf.Level)/2, df = Reliability.N - 1, lower.tail = F) * sqrt(2) * TEM, 2)
df$HighCI.Diff <- round(df$Pre.Post.Diff + qt(p = (1-Conf.Level)/2, df = Reliability.N - 1, lower.tail = F) * sqrt(2) * TEM, 2)
# Summary Stats of Change
Pre.Post.Summary.Stats <- df %>%
group_by(groups) %>%
summarize(
Mean = mean(Pre.Post.Diff),
SD = sd(Pre.Post.Diff))
# SD of the response
diff <- as.data.frame(Pre.Post.Summary.Stats)
sd.response <- sqrt(abs(diff[1,3]^2 - diff[2,3]^2))
# Proportion of Response
mean1 <- diff[1,2]
mean2 <- diff[2,2]
prop.response.group.1 <- ifelse(SWC > 0, 100-pnorm(q = SWC,
mean = mean1,
sd = sd.response)*100, pnorm(q = SWC,
mean = mean1,
sd = sd.response)*100)
prop.response.group.2 <- ifelse(SWC > 0, 100-pnorm(q = SWC,
mean = mean2,
sd = sd.response)*100, pnorm(q = SWC,
mean = mean2,
sd = sd.response)*100)
list(Data = df,
Outcome.Stats = Pre.Post.Summary.Stats,
Stdev.Response = sd.response,
Perct.Responders.Group1 = paste(round(prop.response.group.1, 2), "%", sep = ""),
Perct.Responders.Group2 = paste(round(prop.response.group.2, 2), "%", sep = "")
)
}
Now we are ready to use the outcome function on our simulated intervention data set.
outcome(baseline.test = study.data$baseline, post.test = study.data$post.intervention, groups = study.data$group, subject.IDs = study.data$subject, TEM = 4.83, SWC = 0.756, Reliability.N = 20, Conf.Level = 0.95)
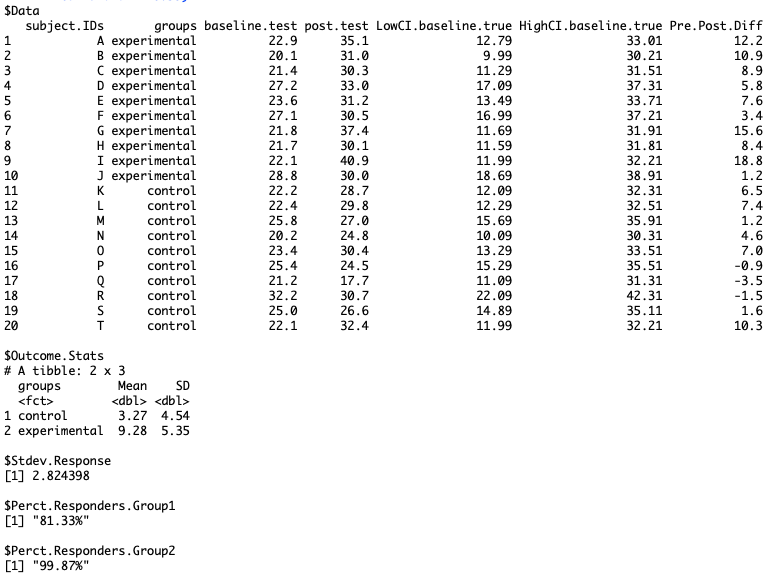
Similar to our test-retest function, the results are returned as a list. Let’s look at the results in more detail:
- The first element of the list provides a table of our original data, except we have a few new columns. First we see that we have Low and High Confidence Interval columns (in this case, these columns represent 95% CI, since that is what I specified when I ran the function). These confidence intervals are specific to the baseline test score. They are important for us to consider because when measuring an athlete we can never be truly confident that the performance they produced is their true performance (due to a variety of factors and, in particular, biological variability). Thus, the function uses the TEM from the test-retest trial to calculate the confidence interval around the athletes’ observed baseline scores. Finally, the last three columns provide us with the post-pre score differences and 95% CI around those difference scores for each individual athlete.
- The second element of list gives us the summary statistics for each group based on how they performed in the trial. In this element, we can see that the experimental group (Group 1, strength training-only group) observed a larger improvement in vertical jump height, on average, following 8 weeks of training, compared to the control group (Group 2, endurance training-only group). TECHNICAL NOTE: R automatically sorted the two groups alphabetically. As such, even though Group 1 (the experimental group) was first in the original data set, it comes out as being “Group 2” in the output.
- The third element is the standard deviation of individual responses. Hopkins6 suggest that this standard deviation represents the amount that the mean effect of the intervention is seen to vary between individuals. This standard deviation will be used in the fourth and fifth elements to help understand the individual responses observed within groups.
- The fourth and fifth elements of the list display the percentage of responders to the treatment. This proportion of response is calculated by evaluating the variability in change scores from the intervention (standard deviation of individual responses) and the specified SWC (from our test-retest trial)2. In the case of our simulated data set we see that Group 1 (remember, this is the endurance group, since R organized the data by group alphabetically) had a lower response than Group 2 (the strength training group).
Wrapping Up
When analyzing data in the applied sport science setting it is important to establish measures such as TEM and SWC so that you can have a higher amount of certainty that athletes are progressing and making true performance improvements. In this blog post, I showed a very simple way to analyze such data while also showing that some basic R coding can be used to produce functions that make our job easier and provide quick results (and quick results are important in the applied setting where decisions between games need to be made in a timely fashion).
Two future considerations:
- The training intervention example I provided may not be terribly realistic in many applied sports settings. For example, rarely will a coach allow the staff to separate players into two groups that train in different ways. In a future blog post, I hope to provide some code for analyzing individuals when serial measurements are taken across a season.
- I didn’t provide any visualization of the data. Data visualization is not only critical to understanding the data you are analyzing but also important for presenting your data to coaches, managers, and other practitioners. I hope to address data visualization approaches in a future blog post.
References
- Hopkins WG, Marshall SW, Batterham AM, Hanin J. (2009). Progressive statistics for studies in sports medicine and exercise science. Med Sci Sports Exer, 41(1): 3-12.
- Swinton PA, Hemingway BS, Saunders B, Gualano B, Dolan E. A statistical framework to interpret individual response to intervention: Paving the way for personalized nutrition and exercise prescription. Front Nutr, 5(41): 1-14.
- Turner A, Brazier J, Bishop C, Chavda S, Cree J, Read P. (2015). Data analysis for strength and conditioning coaches: Using excel to analyze reliability, differences, and relationships. Strength Cond J, 31(1): 76-83.
- Hopkins WG, Batterham AM. (2016). Error rates, decisive outcomes and publication bias with several inferential methods. Sports Med, 46(10): 1563-1573.
- Buchheit M. (2014). Monitoring training status with HR measures: Do all roads lead to Rome? Front Phys, 5(73): 1-19.
- Hopkins WG. (2015). Individual responses made easy. J Apply Physiol, 118: 1444-1446.
Hi, thanks for the great resource! It helped me a lot!
I’ve got a question for establishing SWC (or TEM) in a practical way.
If it is not possible to conduct any reliability tests (i.e. inter- or intra reliability) because of practical issues, it is also possible to use the CV or SEM data derived from research papers to set the SWC or CV% (i.e. research on the reliability of CMJ variables …) ? I’ve seen a paper written by Mathieu Lacome in regards to this, but would like to ask from the practitioner with high experience!
Thank you
Yours Sincerely
Seonghwan Choi