
Earlier this week I shared a method for doing within column iteration in R, as you might do in excel. For example, you want to create a new column that requires a starting value from a different column (or a 0 value) and then requires new values within that column to iterate over the prior values. The way I handled this was to use the accumuate() function available in the {tidyverse} package.
The article got some good feedback and discussion on Twitter. For example, Thomas Mock, provided some examples of using the {slider} package to handle window functions, see HERE and HERE. The package looks to be very handy and easy to use. I’m going have to play around with it some more.
Someone else asked, “how might we do this in a for() loop?”
It’s a good question. Sometimes you might need to use base R or sometimes the for() loop might be easier. So, let’s walk through an example:
Simulate Data
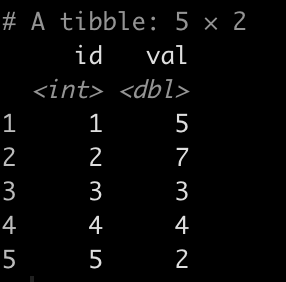
First, we need to simulate a basic data set:
library(tidyverse) df <- tibble( id = 1:5, val = c(5,7,3,4,2) ) df
Setting Up the Problem
Let’s say we want to create a new value that applies a very simple algorithm:
New Value = observed + 2 * lag(new value)
Putting the above data in excel the formula and answer looks like this:
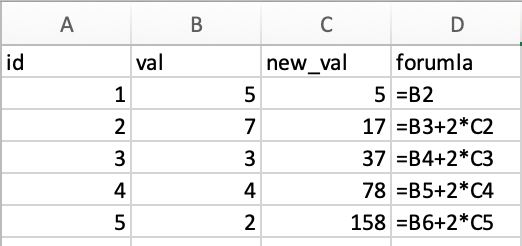
Notice that the first new value starts with our initial observation (5) and then begins to iterate from there.
Writing the for() loop
for() loops can sometimes be scary but if you sequentially think through what you are trying to do you can often come up with a reasonable solution. Let’s step through this one:
- We begin outside of the for() loop by creating two elements. We create N which simply gives us a count of the number of observations in our val column and we create new_val which is nothing more than a place holder for the new values we will create. Notice that the new_val place holder starts with the first element of the df$val column because, remember, we need to begin the new column with our first value observation in the val column. After that, I simply concatenate a bunch of NA values that will be populated with the new values that the for() loop will produce. Notice that I have NA repeat for N-1 times. This is important, as N represents the number of observations in the val column and since we’ve already put a place holder in for the first observation we need to remove one of the NA’s to ensure the new_val column will be the same length as the val column.
- Next, we create our loop. I specify that I want to iterate over all “i” iterations from 2 to N. Why 2? Because the first value is already specified, as discussed above. Inside the for() loop, for each iteration that the loop runs it will store the new value, “i” in the new_val vector we created above. The equation that we specified earlier is within the for loop and I use “i” to index the observations. For example, for the second observation, what the for() loop is doing is saying, df$val[2] + new_val[2 – 1]*2, and for the third time through the loop it says, df$val[3] + new_val[3 – 1]*2, etc. until it goes through all N observations. Everything in the brackets is simply specifying the row indexes.
## We want to create a new value
# New Value = observed + 2 * lag(new value)
# The first value for the new value is the first observation in row one for value
N <- length(df$val)
new_val <- c(df$val[1], rep(NA, N-1))
for(i in 2:N){
new_val[i] <- df$val[i] + new_val[i - 1]*2
}
Once the loop is done running we can simply attach the results to our data frame and see what it looks like:

Same results as the excel sheet!
Wrapping this into a function
After seeing how the for() loop works, you might want to wrap it up into a function so that you don’t need to do the first steps of creating an element for the number of iterations and vector place holder. Also, having it in a function might be useful if you need to frequently use it for other data sets.
We simply wrap all of the steps into a single function that takes an input of the data frame name and the value column that has your most recent observations. Run the function on the data set above and you will obtain the same output.
iterate_column_func <- function(df, val){
N <- length(df$val)
new_val <- c(df$val[1], rep(NA, N-1))
for(i in 2:N){
new_val[i] <- df$val[i] + new_val[i - 1]*2
}
df$new_val <- new_val
return(df)
}
iterate_column_func(df, val)
Applying the function to multiple subjects
What if we have more than one subject that we need to apply the function to?
First, we simulate some more data:
df_2 <- tibble( subject = as.factor(rep(1:10, each = 5)), id = rep(1:5, times = 10), val = round(runif(n = 50, min = 10, max = 20), 0) ) df_2
Next, I’m going to make a slight tweak to the function. I’m going to have the output get returned as a single column data frame.
iterate_column_func <- function(x){
N <- length(x)
new_val <- c(x[1], rep(NA, N-1))
for(i in 2:N){
new_val[i] <- x[i] + new_val[i - 1]*2
}
new_val <- as.data.frame(new_val)
return(new_val)
}
Now, I’m going to apply the custom function to my new data frame, with multiple subjects, using the group_modify() function in {tidyverse}. This function allows us to apply other functions to groups of subjects, iterating over them and producing a data frame as a result.
new_df <- df_2 %>% group_by(subject) %>% group_modify(~iterate_column_func(.x$val)) %>% ungroup()
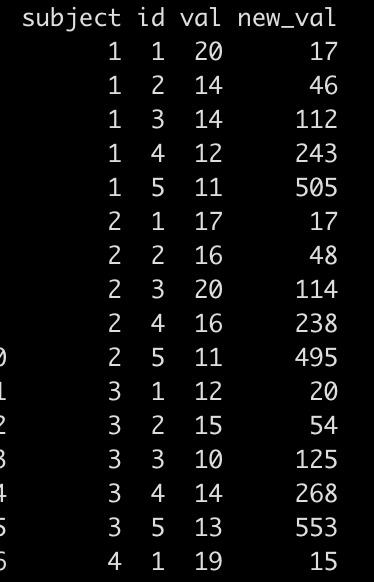
Then, I simply bind this new data to the original data frame and we have our new_val produced within individual.
df_2 %>% bind_cols(new_df %>% select(-subject)) %>% as.data.frame()
Conclusion
And there you go, within column iteration in R, just as you would do in excel. Part 1 covered an approach in {tidyverse} while Part 2 used for() loops in base R to accomplish the same task.
The full code for this article is available on my GitHub page.