Learning a new coding language is always a challenge. One thing that helps me is to create a short tutorial for myself of some of the basic data tasks that I might do when I initially sit down with a data set. I try and think through this in relationship to stuff I might have done (a long, long time ago) in Excel with regards to summarizing data, adding new features, and creating pivot tables.
Since I’m not that great in Python, here is my Doing things in Python that you would normally do in Excel tutorial that may help others looking to get started with this coding language.
The tasks that I cover are:
- Exploring features of the data
- Sorting the columns
- Filtering the columns
- Creating new features
- Calculating summary statistics
- Building pivot tables
- Data visualization
The data I use comes form the pybaseball library, freely available for install in python. I’ll be using the pitchers dataset from years 2012 to 2016.
The entire jupyter notebook is accessible on my GitHub page.
Libraries and Data
The libraries I use are:
- pandas — for working with data frames
- numpy — for additional computational support
- matplotlib & seaborn — for plotting data
- pybaseball — for data acquisition
I called the data set pitchers. The data consists of 408 rows and 334 columns. After doing a bit of exploring the data set (seeing how large it is, checking columns for NA values, etc), we begin by sorting the columns.
Sort Columns
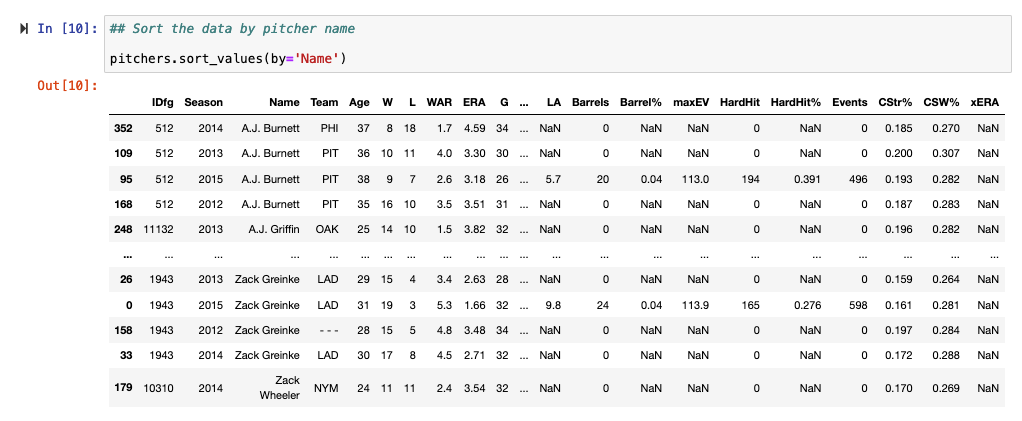
Sorting columns is done by calling the name of the data set and using the sort_values() function, passing it the column you’d like to sort on (in this case, sorting alphabetically by pitcher name)
## Sort the data by pitcher name pitchers.sort_values(by='Name')
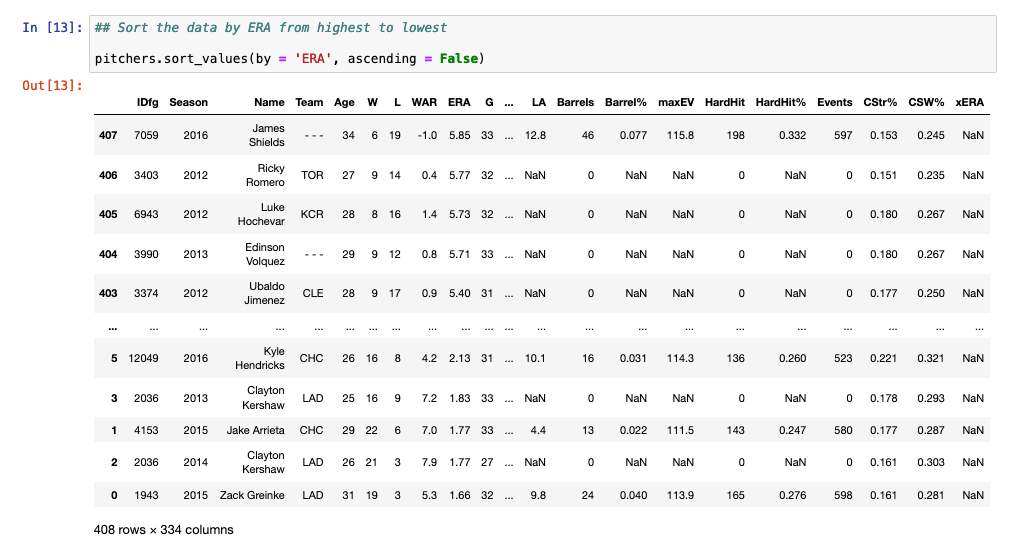
If you have a specific direction you’d like to sort by, set the ‘ascending’ argument to either True or False. In this case, setting ascending = False allows us to sort the ERA from highest to lowest (descending order).
## Sort the data by ERA from highest to lowest pitchers.sort_values(by = 'ERA', ascending = False)
(For additional sorting examples, see the GitHub code)
Filtering Columns
Filtering can be performed by explicitly stating the value you’d like to filter on within the square brackets. Here, I call the data frame (pitchers) and add the .loc function after the data frame name in order to access the rows that are specific to the condition of interest. Here, I’m only interested in looking at the 2012 season. Additionally, I only want a few columns (rather than the 334 from the full data set). As such, I specify those columns AFTER the comma within the square brackets. Everything to the left of the comma is specific to the rows I want to filter (Season == 2012) and everything to the right of the comma represents the columns of interest I’d like returned.
## Filter to only see the 2012 season # Keep only columns: Name, Team, Age, G, W, L, WAR, and ERA season2012 = pitchers.loc[pitchers['Season']== 2012, ['Name', 'Team', 'Age', 'G', 'W', 'L', 'WAR', 'ERA']] season2012.head()

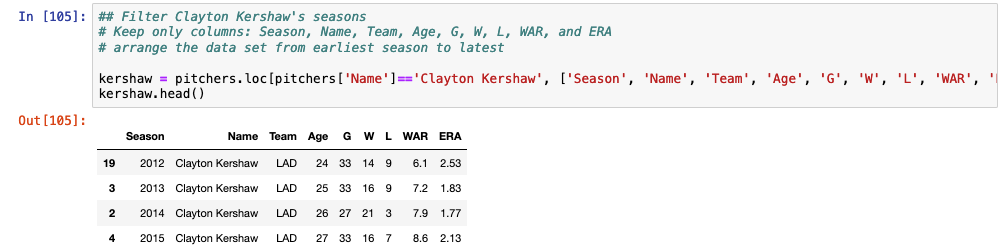
If I only want to look at Clayton Kershaw over this time period, I can filter him out like so:
## Filter Clayton Kershaw's seasons
# Keep only columns: Season, Name, Team, Age, G, W, L, WAR, and ERA
# arrange the data set from earliest season to latest
kershaw = pitchers.loc[pitchers['Name']=='Clayton Kershaw', ['Season', 'Name', 'Team', 'Age', 'G', 'W', 'L', 'WAR', 'ERA']].sort_values('Season', ascending = True)
kershaw.head()
To make the data set more palatable for the rest of the tutorial, I’m going to create a smaller data set, with fewer columns (pitchers_small).
## Create a smaller data set # Keep only columns: Season, Name, Team, Age, G, W, L, WAR, ERA, Start-IP, and Relief-IP # arrange the data set from earliest season to latest for each pitcher pitchers_small = pitchers[['Season', 'Name', 'Team', 'Age', 'G', 'W', 'L', 'WAR', 'ERA', 'Start-IP','Relief-IP']].sort_values(['Name', 'Season'], ascending = True) pitchers_small.head(30)

Creating New Features
I create three new features in the data set:
- A sequence counter that counts the season number of each pitcher from 1 to N seasons that they are in the data set.This is done by simply grouping the data by the pitcher name and then cumulatively counting each row that the pitcher is seen in the data. Notice I add “+1” to the end of the code because python begins counter at “0”. NOTE: To make this work properly, ensure that the data is ordered by pitcher name and season. I did this at the end of my code, in the previous step.
- An ‘age group’ feature that groups the ages of the pitchers in 5 year bins.To accomplish this task, I use a 3 step process. First, I specify where I want the age bins to occur and assign it to the bins variable. I then create the labels I would like to correspond to each of the bins and assign that to the age_group variable. Then I use the np.select() function to combine this information, assigning it to a new column in my data set called ‘age_group‘.
- A ‘pitcher type’ feature that considers anyone who’s starter innings pitched was greater or equal to the median number of starting innings pitched as a ‘starter’ and all others as ‘relievers’.To create the pitcher_type column, I use the np.where() function, which works like ifelse() or case_when() in R or like IF() in excel. The first argument is the condition I’d like checked (“did this pitcher have starter innings pitched that were greater than or equal to the median number of starter innings pitched?). If the condition is met, the function will assign the pitcher in that row as a “starter”. If the condition is not met, then the pitcher in that row is designated as a “reliever”.
## Add a sequence counter for each season for each pitcher
pitchers_small['season_id'] = pitchers_small.groupby(['Name']).cumcount() + 1
## Create a new column called 'age_group'
# create conditions for the age_group bins
bins = [
(pitchers_small['Age'] <= 25), (pitchers_small['Age'] > 25) & (pitchers_small['Age'] <= 30), (pitchers_small['Age'] > 30) & (pitchers_small['Age'] <= 35), (pitchers_small['Age'] > 35) & (pitchers_small['Age'] <= 40), (pitchers_small['Age'] > 40)
]
# create the age_group names to be assigned to each bin
age_group = ['<= 25', '25 to 30', '31 to 35', '36 to 40', '> 40']
# add the age_group bins into the data
pitchers_small['age_group'] = np.select(bins, age_group)
## Create a pitcher_type column which makes a distinction between starters and relievers
pitchers_small['pitcher_type'] = np.where(pitchers_small['Start-IP'] >= pitchers_small['Start-IP'].median(), 'starter', 'reliever')
pitchers_small.head()

Calculating Summary Statistics
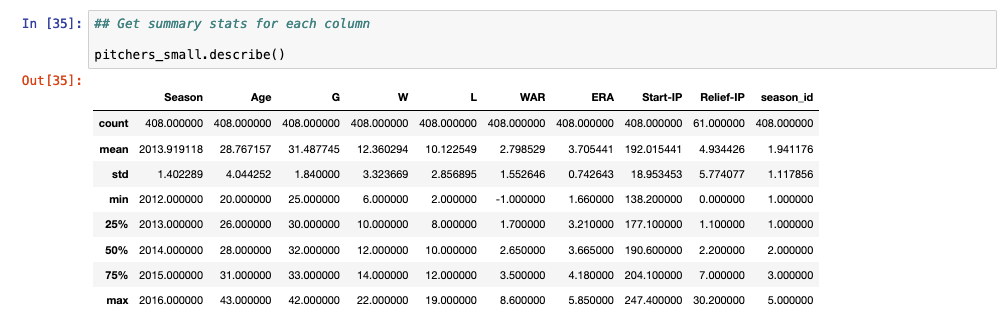
The GItHub repo for this post offers a few ways of obtaining the mean, standard deviation, and counts of values for different columns. For simplicity, I’ll show a convenient way to get summary stats over an entire data set using the describe() function, which is called following the name of the data frame and a period.
## Get summary stats for each column pitchers_small.describe()
Pivot Tables
There are a few ways to create a pivot table in python. One way is to use the groupby() function for the class you’d like to summarize over and then call the mathematical operation (e.g., mean) you are interested in. I have an example of this in the GitHub post in code chuck 42 as well as several examples of other pivot table options. Another way is to use the pivot_table() function from the pandas library.
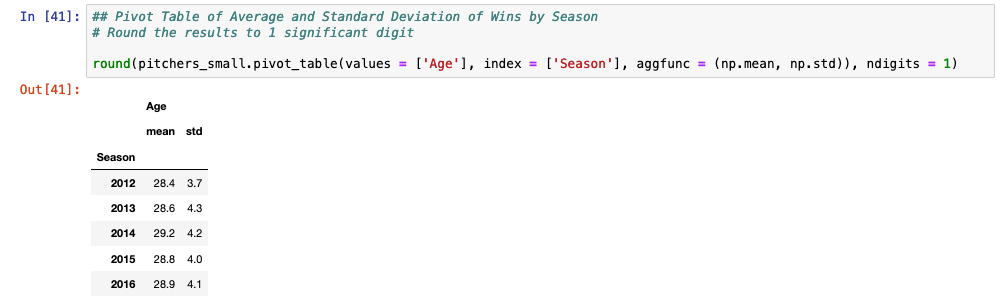
Below is a pivot table of the mean and standard deviation of pitcher age across the 5 seasons in the data set.
## Pivot Table of Average and Standard Deviation of Wins by Season # Round the results to 1 significant digit round(pitchers_small.pivot_table(values = ['Age'], index = ['Season'], aggfunc = (np.mean, np.std)), ndigits = 1)
You can also make more complicated pivot tables by setting the columns to a second grouping variable, as one would do in Excel. Below, we look at the average WAR across all 5 seasons within the 5 age groups (which we created in the previous section).
## Calculate the average WAR per season across age group pitchers_small.pivot_table(values = ['WAR'], index = ['Season'], columns = ['age_group'], aggfunc = np.mean)

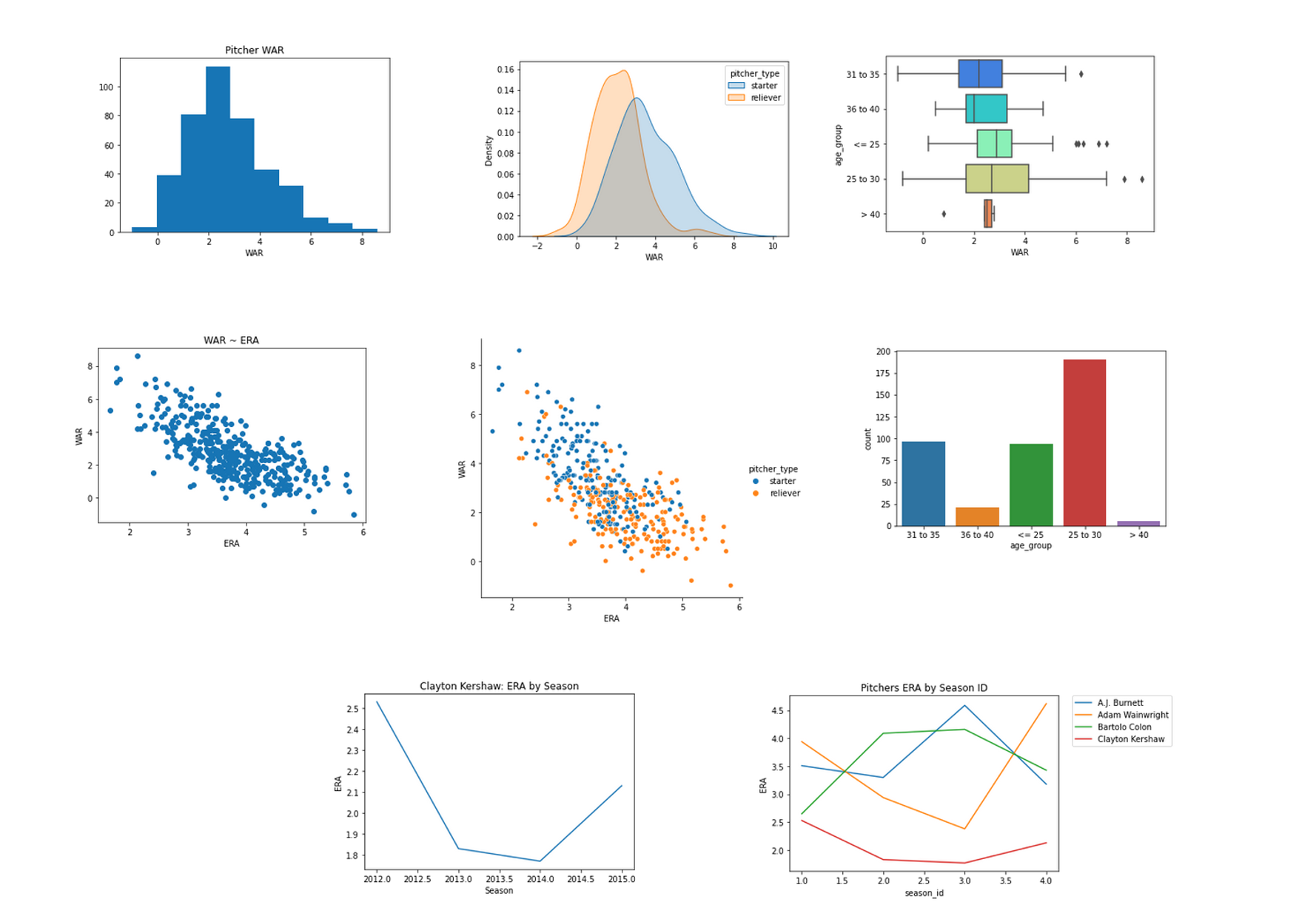
Data Visualization
In the GitHub post I walk through how to plot 8 different plots:
- Histogram
- Density plots by group
- Boxplots by group
- Scatter plot
- Scatter plot highlighting groups
- Bar plots for counting values
- Line plot for a single player over time
- Line plots for multiple players over time