
Summarizing and visualizing your data is a critical first step of analysis. For new PhD students and those new to R, I’ve put together a few of the common approaches one might take when dealing with data. This tutorial covers:
- Manipulating/reshaping a data frame (from wide format to long format).
- Basic functions for obtaining summary statistics in your data .
- Visualization strategies such as boxplots, histograms, violin plots, joint plots, and plots showing inter-individual differences.
Instead of putting all of the code into this blog post I’ll just highlight some of the key pieces along the way. If you want all of the code, simply head over to my GitHub page.
Data
In this tutorial, we will simulate data where twenty participants are randomized to either a traditional (IE, linear) or block periodization program for 16-weeks. The participants had their squat tested pre and post training program intervention and the difference between the two tests is our outcome of interest. (NOTE: I drew random values for pre- and post-squat for both groups in this example, so it isn’t completely life like, where the post-test would normally be related in some way to the pre-test. In future simulations that discuss analysis I will use more realistic outcomes).
Here is a snip of what the simulation code and first few rows of the data look like:


Packages
This analysis will use three R packages (make sure you have installed them prior to running the code):
- {tidyverse} – Used for data manipulation and visualization
- {gridExtra} – Used for organizing the plot grid when creating our joint plot
- {psych} – Used to produce simple summary statistics
Manipulating Data
Occasionaly, you may need to manipulate your data from a wide format to a long format, or vice versa, as some types of analysis or visualizations are made easier when the data is in a specific format.
In our case, we have the data in a wide format. In this format, we have one row per participant and the 2 columns of interest are the pre- and post-squat columns (see above example of the first 6 rows). This can be accomplished with the pivot_longer() function in {tidyverse}. This function takes four primary arguments:
- The data frame where our wide format data is.
- The columns of interest from our wide data frame that we want to pivot into a single column. In this case, “pre_squat” and “post_squat” columns are the ones we want to pivot.
- the names_to argument is where we specify the name of the column where the pre_squat and post_squat columns will be pivoted into.
- The values_to column is where we specify the name of the column that we want the values of our participants pre_squat and post_squat values to reside under in the long data frame.
The code looks like this:
dat_long <- pivot_longer(data = dat,
cols = c("pre_squat", "post_squat"),
names_to = "test",
values_to = "performance")
The first few rows of the long format data frame look like this:
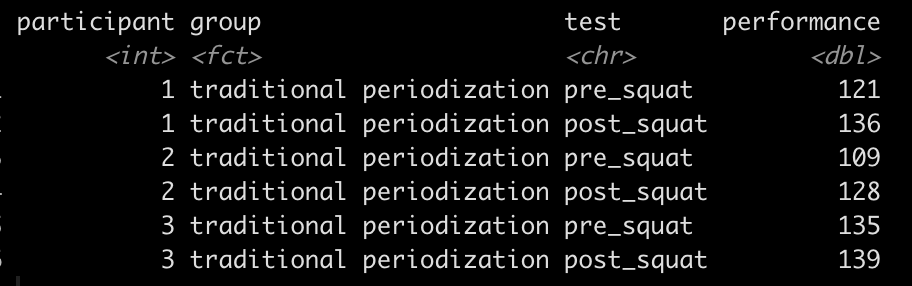
Notice that now each participant has two rows of data, one for their pre-squat and one for their post-squat.
If we have stored our data in a long format and we need to go back to a wide format, we can simply use pivot_wider() from {tidyverse}. This function takes three primary arguments:
- The data frame where our long format data is.
- The names_from argument, which specifies the column in the long data frame that has the variables we’d like to pivot out into their own columns in a wide format (in this case, the “test” column contains the information about whether the test performed was pre or post, so we want to pivot that out to two new columns).
- The values_from argument specifies which values we want to fill under the corresponding columns we are pivoting. In this case, the ‘performance’ column has the data specific to the pre- and post-squat variables that we are pivoting to their own columns.
The code looks like this:
dat_wide <- pivot_wider(data = dat_long,
names_from = test,
values_from = performance)
The first few rows of the new wide data frame looks like this:
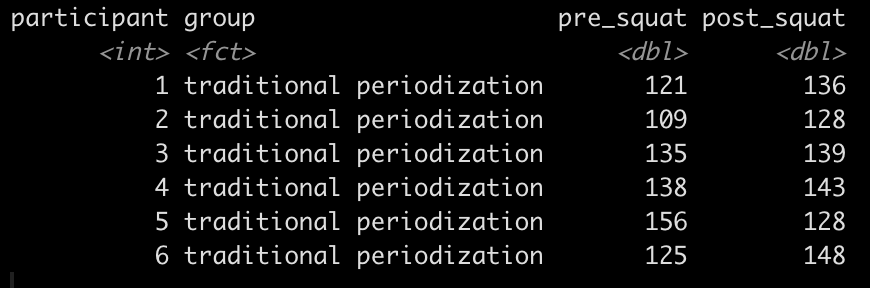 Notice that the data looks exactly like our initial data frame (as you would expect given that original data was already a wide data frame) with one row per participant.
Notice that the data looks exactly like our initial data frame (as you would expect given that original data was already a wide data frame) with one row per participant.
Producing Summary Statistics
Now that we’ve walked through some simple approaches to manipulating data frames, I’ll detail a few easy ways of summarizing your data.
The {psych} package has two very simple functions, describe() and describeBy(), which come in handy when you need summary statistics, info about the range of the data, the standard error of the data, and some metrics about the distribution of your data.
describe() works with all of the data in a column. All you need to do is specify the data frame and the column of interest (separate those two by a $ sign). In this case, we will use the long data frame and produce summary statistics for the performance of pre-and post-squat performance across all subjects.
describe(dat_long$performance)

describeBy() functions similar to describe(); however, it allows for a second argument identifying the group that you’d like to produce summary statistics for. In this case, we will produce summary statistics for all pre- and post-squat performance data described by group (traditional or block periodization).
describeBy(dat_long$performance, dat_long$group)
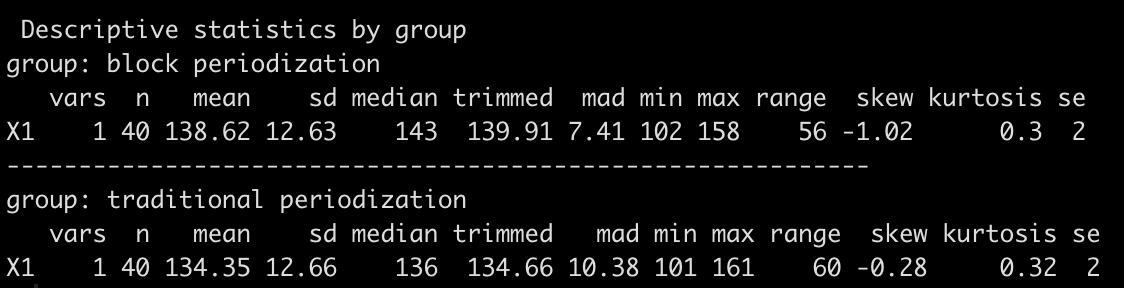
What if we want to look at summary statistics by group but further group by pre- and post-squat performance? In this instance, we can code our own summary statistics using {tidyverse}. {tidyverse} is one of the best packages for data manipulation, data clean up, and data visualization as it contains a host of other packages that contain functions for these tasks.
In the below code I start with the data frame that has the data I want to summarize and I ‘pipe’ together different functions using the %>% command. This allows me to iterate very quickly on a data set and intuitively build analysis as I go. In this example I first call the mutate() function (used to add a new column to my already existing data set) and inside of it I re-level my factors (since R automatically stores them in alphabetical order) as I want my results returned with the pre-squat performance first followed by the post-squat performance. After that step, I indicate that I want to group_by() both my periodization groups (traditional and block) and my test (pre and post). Finally, I use the summarize() function to create a summary data frame where I am specifying N = n(), in order to get the sample size counted in each group of my group_by(), as well as the mean and the standard deviation for each of the group_by() groups.
dat_long %>%
mutate(test = fct_relevel(test, levels = c("pre_squat", "post_squat"))) %>%
group_by(group, test) %>%
summarize(N = n(),
Mean = mean(performance),
SD = sd(performance))

NOTE: In my R script on GItHub I also create a “difference” column (post – pre) and perform the same descriptive operations on that column as above. We will use this column below to produce quantiles as well as for our data visualization purposes but feel free to work through the examples in the R code for using the above functions.
Producing quantiles is easy with the quantile() function from base R. Similar to describe() above, pass the function the data and the column of interest, separated by a $ sign, to get your result. Here we will get the quantiles of the differences between post and pre-squat strength for all participants.
quantile(dat$Diff)

If we’d like to see these differences by group, we can use the by() function, which allows us to pass a function (in this case quantile()) to an entire data frame. As such, we will get the quantiles for the difference in performance by group.
by(dat$Diff, dat$group, quantile)
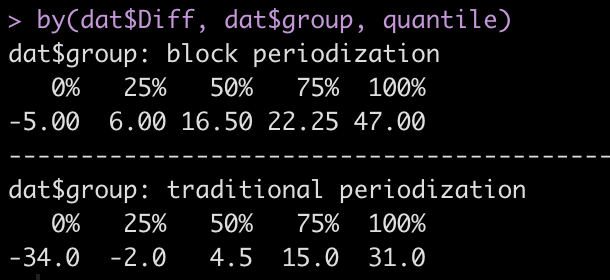
Note: In the R script on my GitHub page I walk through how to create a sequence of numbers (form 0 to 1) and specify a broader range of quantiles to be returned, should you need them.
Data Visualization
Below are a few ways that we can visualize the between group differences (the code for these is located at GitHub). All of the coding was done using {tidyverse}.
Boxplots
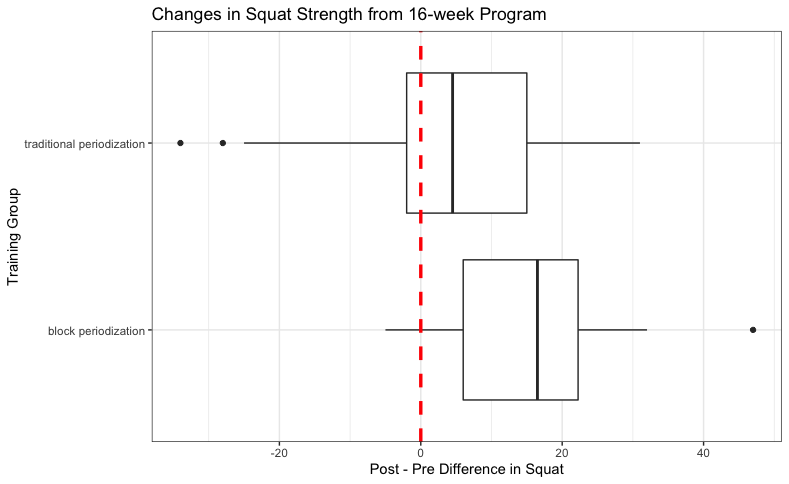
Boxplots are for showing the quantiles of your data but can lack context. The box represents the interquartile range (25-75) and the black line within the box represents the median value. All of these values as well as the smallest and largest values were obtained in the quantile() function in the previous section. We can see that the median value of the difference in squat performance for the block periodization group is higher than that of the traditional periodization group.
Overlapping Histograms
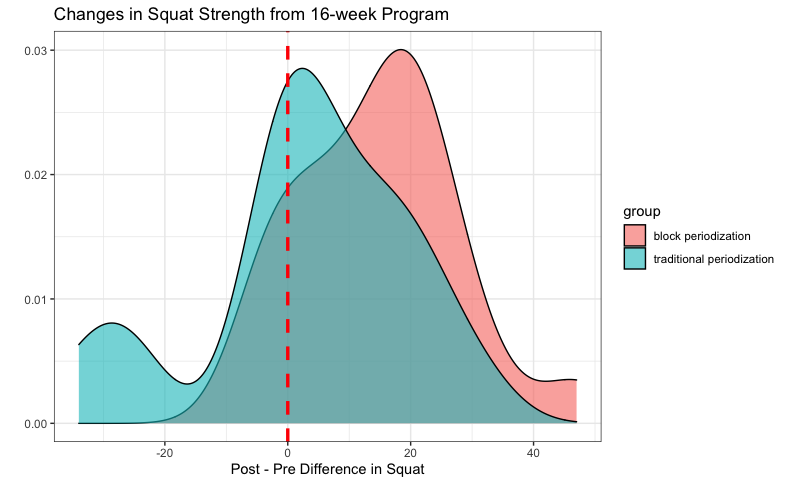
Overlapping histograms are useful for showing distributions and the difference between two groups. The dotted red line is set at a difference of 0 to represent no change from pre- to post-squat test performance. The alpha argument is set below 1 inside the geom_histogram() function of the code allow some opaqueness of the histograms. This way, we can see both distributions clearly. Similar to the boxplots, we can see that the median value of the difference in squat performance for the block periodization group is higher than that of the traditional periodization group.
Violin Plots with Points
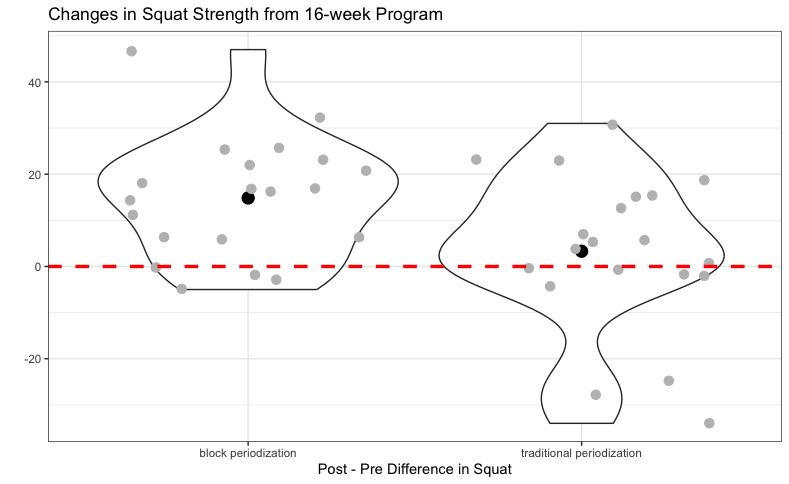
Violin plots are a nice balance between boxplots and histograms as they are essentially two histograms mirroring each other. As such, you get tan appreciation of the data distribution, as you would with a histogram, while visualizing the groups side-by-side, as you would with a boxplot. I kept all of the data ponts on the plot as well, to allow the reader to see each participants performance and I placed a thick black point in the middle of the violin to represent the group median.
Joint Plot
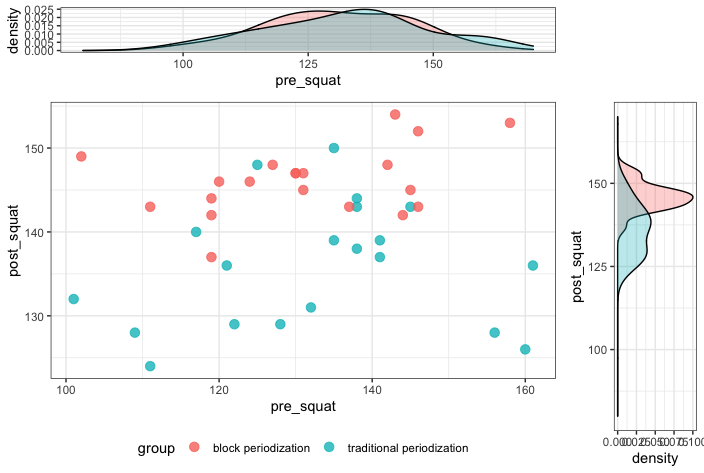
Joint plots are a nice way to visualize continuous data where you have an ‘x’ and ‘y’ variable and want to additionally reflect the distribution of each variable with a histogram in the margins. In this plot, I placed the pre-squat performance on the x-axis and the post-squat performance on the y-axis and colored the points by which group the participant was in. This plot was constructed in {tidyverse} but requires the {gridExtra} package to arrange the histograms for the x and y variables in the margin. Additionally, you’ll want to create an empty plot to take up space on the grid so that everything lines up. This is all detailed in the code.
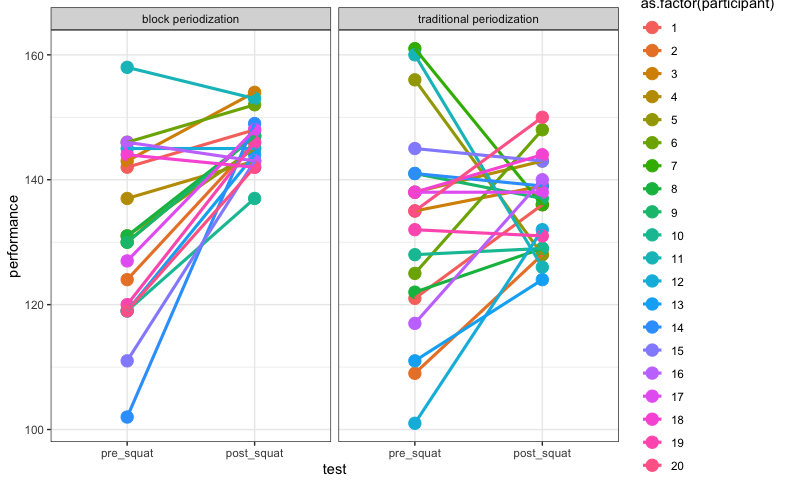
Inter-individual Differences
Finally, as we can see from all of the above plots, while the average performance in the block periodization group was greater than that of the traditional periodization group, there are large distributions in both groups indicating that some participants improved, others did not, and some stayed the same. We can visualize these inter-individual responses by creating a visaluzation that exposes each participant’s performance on both tests.
Conclusion
Hopefully this post serverse as a jumping off point for those looking to get started with analyzing data in R. As I stated at the start, all data can be obtained at my GitHub page.